Extend LLMs to infinite length without sacrificing efficiency and performance, without retraining

Project description
Attention Sinks in Transformers for endless fluent generation
TL;DR: attention_sinks adapts pre-trained LLMs to use a modified form of sliding window attention that remains able to produce fluent text indefinitely.
Benchmark Findings
See Benchmark Setups for information on how these benchmarks were carried out.
Perplexity
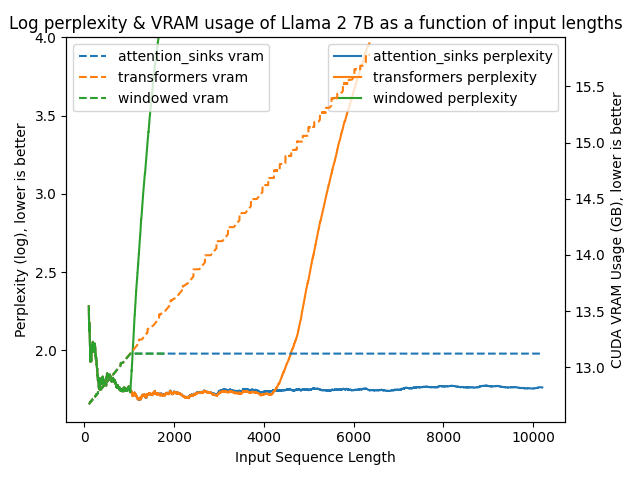
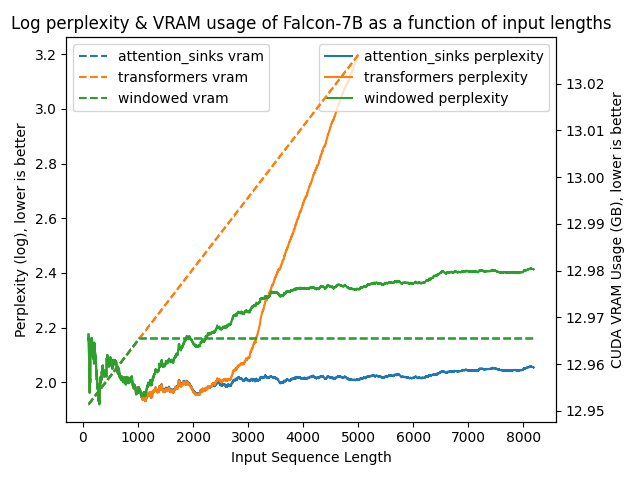
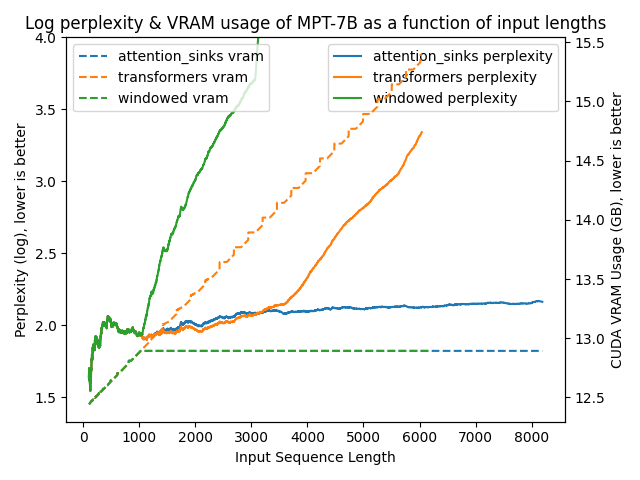
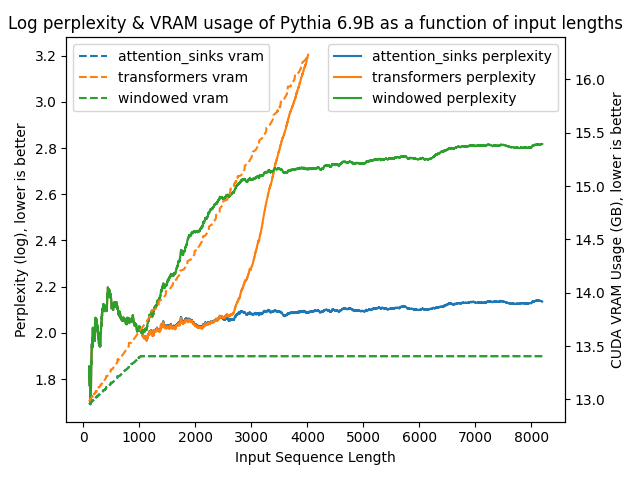
The following figures plot model perplexities under the various different approaches. A higher perplexity is indicative that the model is losing the ability to produce proper language.
| Llama-2-7b-hf | Falcon-7B |
|---|---|
 |
 |
| MPT-7B | Pythia-6.9B |
 |
 |
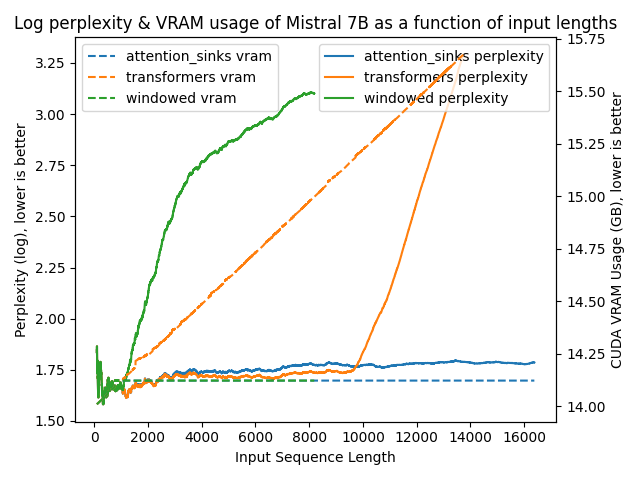
| Mistral-7B-v0.1 | GPT-J-6B |
 |
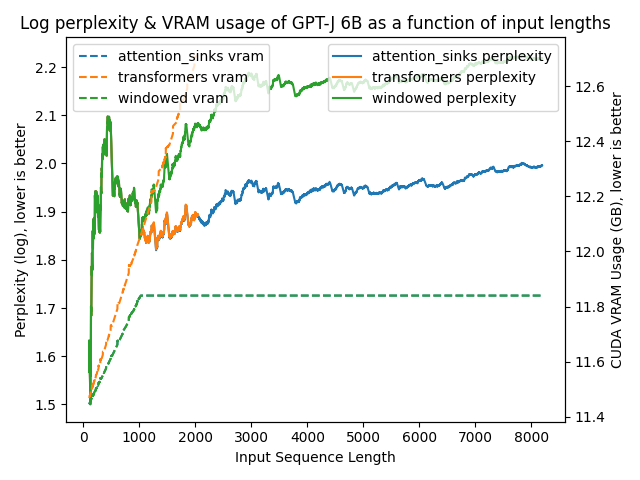 |
The results are clear as day:
transformers: The VRAM usage is linear as it doesn't do any windowing. The performance heavily falls after ~4096 tokens.windowed: The VRAM is constant usage due to the windowing at 1024 tokens. However, it fails as soon as the first tokens leave the window.attention_sinks: Constant VRAM usage due to windowing with 4 attention sink tokens + the 1020 most recent tokens. This approach never fails despite the constant VRAM usage.
Fluency during endless generation
See here text generated by the same Llama 2 7B model using the same settings, but loaded using:
transformers: Loses fluency after ~1900 tokens and starts endlessly generating broken unicode characters like🤖🧠👨���������������������❌.windowattention: Loses fluency after ~1000 tokens, generates hundreds of newlines interspersed with text likeOOOMMO̶OANOOAMOO̶OMMO❌.attention_sinks: Fluent for the full 10k tokens of the test ✅.
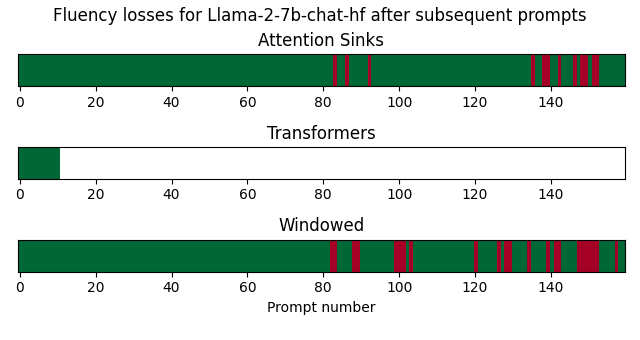
Fluency during subsequent prompting for chat-style LLMs
In this benchmark, I sent subsequent prompts from MT-Bench through the model and automatically detect when fluency gets lost. For Llama-2-7b-chat, transformers runs out of VRAM, so it can only handle a handful of subsequent prompts. For MPT-7B-chat, a RuntimeError is encountered for transformers when the input length exceeds 2048.
| Mistral-7B-Instruct-v0.1 | Llama-2-7b-chat-hf |
|---|---|
 |
 |
| MPT-7B-chat | |
 |
Loading models using attention_sinks has a very positive impact on the fluency of the models across subsequent prompts. However, as can be seen for Llama-2-7B-chat-hf, it does not completely avoid fluency issues. See demo/streaming_logs for the full logs.
Overview
This repository is an open-source implementation of the Efficient Streaming Language Models with Attention Sinks paper.
- Extend existing LLMs (e.g. Llama 2) to produce fluent text indefinitely without sacrificing efficiency and performance, without any retraining. Ideal for multi-step LLMs, e.g. chat assistants.
- Model perplexities were stable even after 4 million tokens!
- Unlike with regular
transformers, memory usage is constant and thus the inference does not get extremely slow due to memory issues at higher sequence lengths. - Models using attention sinks have been shown to perform very well at the task of recalling a value from 20 lines back, even if the model has already processed hundreds of thousands of lines, whereas models using regular dense or window attention fall to 0% after having processed a few thousand tokens.
- The
attention_sinksAPI allows for a drop-in replacement of thetransformersAPI:from attention_sinks import AutoModel model = AutoModel.from_pretrained("meta-llama/Llama-2-7b-hf", device_map="auto")
- Support for Llama, Mistral, Falcon, MPT, GPTNeoX (Pythia) and GPT-J models.
- Note: All of these models must be loaded without
trust_remote_code=True.
- Note: All of these models must be loaded without
- New parameters to
AutoModel....from_pretrained:attention_sink_size,int, defaults to 4: The number of initial tokens to use as the attention sink. These tokens are always included in the Attention Sink KV Cache.attention_sink_window_size,int, defaults to 1020: The size of the sliding window, i.e. the number of "recent tokens" to include in the Attention Sink KV Cache. A larger window size costs more memory.
See also the FAQ for further details.
Installation
You can install attention_sinks like so
pip install attention_sinks
Usage
Loading any Llama, Mistral, Falcon, MPT, GPTNeoX (Pythia) and GPT-J model is as simple as loading it in transformers, the only change is that the model class must be imported from attention_sinks rather than transformers, e.g.:
from attention_sinks import AutoModel
model = AutoModel.from_pretrained("mosaicml/mpt-7b", device_map="auto")
Generation can be done like you would expect from transformers, e.g. like so:
import torch
from transformers import AutoTokenizer, TextStreamer, GenerationConfig
from attention_sinks import AutoModelForCausalLM
# model_id = "meta-llama/Llama-2-7b-hf"
# model_id = "mistralai/Mistral-7B-v0.1"
model_id = "mosaicml/mpt-7b"
# model_id = "tiiuae/falcon-7b"
# model_id = "EleutherAI/pythia-6.9b-deduped"
# Note: instruct or chat models also work.
# Load the chosen model and corresponding tokenizer
model = AutoModelForCausalLM.from_pretrained(
model_id,
# for efficiency:
device_map="auto",
torch_dtype=torch.float16,
# `attention_sinks`-specific arguments:
attention_sink_size=4,
attention_sink_window_size=252, # <- Low for the sake of faster generation
)
model.eval()
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
# Our input text
text = "Vaswani et al. (2017) introduced the Transformers"
# Encode the text
input_ids = tokenizer.encode(text, return_tensors="pt").to(model.device)
with torch.no_grad():
# A TextStreamer prints tokens as they're being generated
streamer = TextStreamer(tokenizer)
generated_tokens = model.generate(
input_ids,
generation_config=GenerationConfig(
# use_cache=True is required, the rest can be changed up.
use_cache=True,
min_new_tokens=100_000,
max_new_tokens=1_000_000,
penalty_alpha=0.6,
top_k=5,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
),
streamer=streamer,
)
# Decode the final generated text
output_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
This example will happily generate between 100k and 1m tokens without forgetting how to speak, even on a low-VRAM environment like Google Colab when using load_in_4bit=True in the AutoModelForCausalLM.from_pretrained.
Demos
You can find a demo script for this endless generation in demo/endless_generation.py. I already ran this script a few times, resulting in logs for up to 10000 tokens using attention_sinks, transformers and windowed (attention) with Llama 2 7B. The generation settings aren't ideal, but the logs clearly show that Llama 2 7B with attention_sinks is the only approach that remains able to generate fluent text.
However, if you want to do multi-step generation, which is what attention_sinks models are well suited for, then you'll want to try the demo/streaming.py demo. This approach is required as the regular model.generate does not return the required past_key_values parameter to be passed as history in the next prompt.
Benchmark Setups
Perplexity
I've measured the perplexity by computing the negative loss likelihoods against a large text, specifically a book from the pg19 dataset.
A collection of ready-to-go scripts have been prepared in benchmark/scripts for various model architectures like Llama 2, Falcon, MPT, Mistral and GPT-NeoX (Pythia). Each of these scripts runs the benchmarking and plotting tools described below for pure transformers, attention_sinks and a third alternative: windowed, which involves simple windowed attention at a window size of 1024 tokens. Upon completion, the script will plot the figures from Benchmark Findings.
The benchmark directory also contains directories with outputs of the perplexity benchmarking tool.
Run the benchmarking scripts
Benchmarking tool
You can run a few benchmarks to compute the perplexity of various models over time using the provided perplexity.py benchmarking script. This is done by computing the negative log likelihood losses of the chosen model when it is provided a full book with 60k+ tokens. By default, the scripts stop after 8192 tokens, but this can be modified. An ideal solution continuously has a low log perplexity and a constant CUDA VRAM usage.
To use the script, you can run:
python benchmark/perplexity.py --experiment attention_sinks
Full argument list
usage: perplexity.py [-h] [--experiment {attention_sinks,transformers,windowed}] [--model_name_or_path MODEL_NAME_OR_PATH] [--revision REVISION]
[--trust_remote_code] [--dataset_name DATASET_NAME] [--data_column DATA_COLUMN] [--task TASK] [--split {validation,test}]
[--num_tokens NUM_TOKENS] [--output_dir OUTPUT_DIR] [--window_size WINDOW_SIZE] [--attention_sink_size ATTENTION_SINK_SIZE]
options:
-h, --help show this help message and exit
--experiment {attention_sinks,transformers,windowed}
--model_name_or_path MODEL_NAME_OR_PATH
--revision REVISION
--trust_remote_code
--dataset_name DATASET_NAME
--data_column DATA_COLUMN
--task TASK
--split {validation,test}
--num_tokens NUM_TOKENS
--output_dir OUTPUT_DIR
--window_size WINDOW_SIZE
--attention_sink_size ATTENTION_SINK_SIZE
This script will create a csv file in the output directory ("benchmarks/outputs" by default) for that experiment, with information about perplexities, CUDA VRAM usage and latencies.
Plotting tool
The information from the benchmarking tool can be plotted using the plot_perplexity.py script. In particular, you can plot any combination of the following features:
perplexity,vram, i.e. CUDA VRAM usage,latency.
For example:
python benchmark/plot_perplexity.py --features perplexity latency --title "Log perplexity & latency of Llama 2 7B as a function of input lengths"
Full argument list
usage: plot_perplexity.py [-h] [--output_dir OUTPUT_DIR] [--features {perplexity,vram,latency} [{perplexity,vram,latency} ...]] [--title TITLE]
[--log_perplexity_limit LOG_PERPLEXITY_LIMIT] [--skip_first SKIP_FIRST]
options:
-h, --help show this help message and exit
--output_dir OUTPUT_DIR
--features {perplexity,vram,latency} [{perplexity,vram,latency} ...]
--title TITLE
--log_perplexity_limit LOG_PERPLEXITY_LIMIT
--skip_first SKIP_FIRST
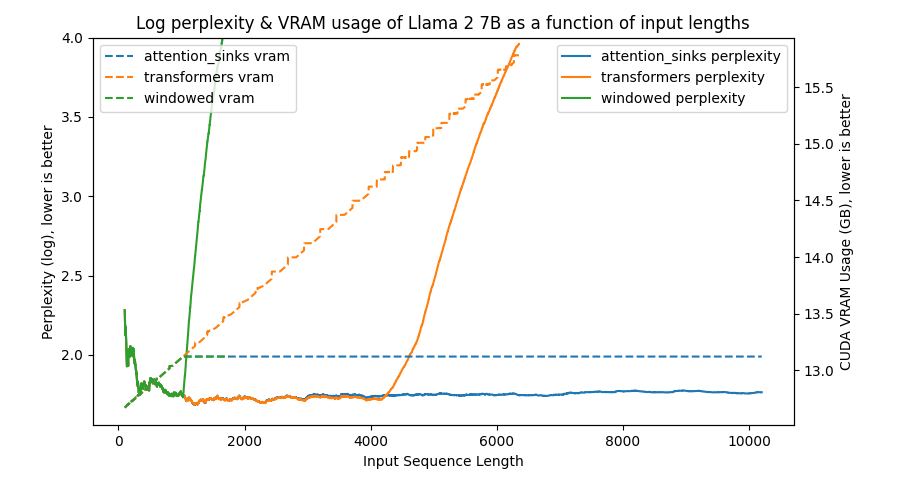
This script takes all csv files from the output directory ("benchmark/outputs" by default), and creates a plot like so:
python benchmark/plot_perplexity.py --features perplexity vram --title "Log perplexity & VRAM usage of Llama 2 7B as a function of input lengths" --output_dir benchmark/outputs_llama_2_7b --log_perplexity_limit 4
Fluency during endless generation
I've measured the fluency during endless generation by running demo/endless_generation.py using attention_sinks, transformers, and windowed modes. I ran this script with Llama-2-7B-hf for up to 10000 tokens and manually observed the outputs, which are logged in attention_sinks, transformers and windowed (attention).
I stopped the generations after I observed loss of fluency.
Fluency across subsequent prompts for chat-style LLMs
I've measured the fluency across subsequent prompts by running demo/streaming.py using attention_sinks, transformers and windowed modes, and parsing the logs. In particular, I automatically classified a response as a failure if it:
- contains less than 26 different characters, and
- is more than 1000 tokens long.
FAQ
This FAQ was created by the paper authors:
-
What does "working on infinite-length inputs" imply for LLMs?
Handling infinite-length text with LLMs presents challenges. Notably, storing all previous Key and Value (KV) states demands significant memory, and models might struggle to generate text beyond their training sequence length. Attention Sink models addresses this by retaining only the most recent tokens and attention sinks, discarding intermediate tokens. This enables the model to generate coherent text from recent tokens without a cache reset — a capability not seen in earlier methods.
-
Is the context window of LLMs expanded?
No. The context window remains unchanged. Only the most recent tokens and attention sinks are retained, discarding middle tokens. This means the model can only process the latest tokens. The context window remains constrained by its initial pre-training. For instance, if Llama-2 is pre-trained with a context window of 4096 tokens, then the maximum cache size for an Attention Sink model on Llama-2 remains 4096.
-
Can I input an extensive text, like a book, into an Attention Sink model for summarization?
While you can input a lengthy text, the model will only recognize the latest tokens. Thus, if a book is an input, an Attention Sink model might only summarize the concluding paragraphs, which might not be very insightful. As emphasized earlier, we neither expand the LLMs' context window nor enhance their long-term memory. An Attention Sink model's strength lies in generating fluent text from recent tokens without needing a cache refresh.
-
What is the ideal use case for Attention Sink models?
Attention Sink models are optimized for streaming applications, such as multi-round dialogues. It's ideal for scenarios where a model needs to operate continually without requiring extensive memory or dependency on past data. An example is a daily assistant based on LLMs. Attention Sink models would let the model function continuously, basing its responses on recent conversations without needing to refresh its cache. Earlier methods would either need a cache reset when the conversation length exceeded the training length (losing recent context) or recompute KV states from recent text history, which can be time-consuming.
-
How does the Attention Sink approach relate to recent works on context extension?
The Attention Sink method is orthogonal to recent context extension methods and can be integrated with them. In the context of Attention Sink models, "context extension" refers to the possibility of using a larger cache size to store more recent tokens. For a practical demonstration, refer to Figure 9 in the paper, where LongChat-7B-v1.5-32K and Llama-2-7B-32K-Instruct are adapted with Attention Sinks.
Changelog
See CHANGELOG.md for all release information.
Credits
Inspired by, and adapted from StreamingLLM.
Citation
@article{xiao2023streamingllm,
title={Efficient Streaming Language Models with Attention Sinks},
author={Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike},
journal={arXiv},
year={2023}
}


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
File details
Details for the file attention_sinks-0.2.3.tar.gz.
File metadata
- Download URL: attention_sinks-0.2.3.tar.gz
- Upload date:
- Size: 29.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | d1506a2563ab6a580db46feb2577a60c23e1f65ca196af8e0cc3cc8b6d7a5561 |
|
| MD5 | b4d0036ed77660e7f27505ae2b839aa9 |
|
| BLAKE2b-256 | f50463fd78a3f9efece8cdcf9b27d61763836267630154d1bb63425071fc7122 |
File details
Details for the file attention_sinks-0.2.3-py3-none-any.whl.
File metadata
- Download URL: attention_sinks-0.2.3-py3-none-any.whl
- Upload date:
- Size: 35.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 578d4d0c3ba22072c12403a63b356686b857cd7d194a33de86de95bd37a4af33 |
|
| MD5 | 931de6c2ac1fc42d00afab4767ccffd2 |
|
| BLAKE2b-256 | b392e147b47ea2df019b3922d431b7a7dffb89c117a064a60c027b816f1b2f36 |







