Cadasta Worker Toolbox

Project description



A collection of helpers to assist in quickly building asynchronous workers for the Cadasta system.
Architecture
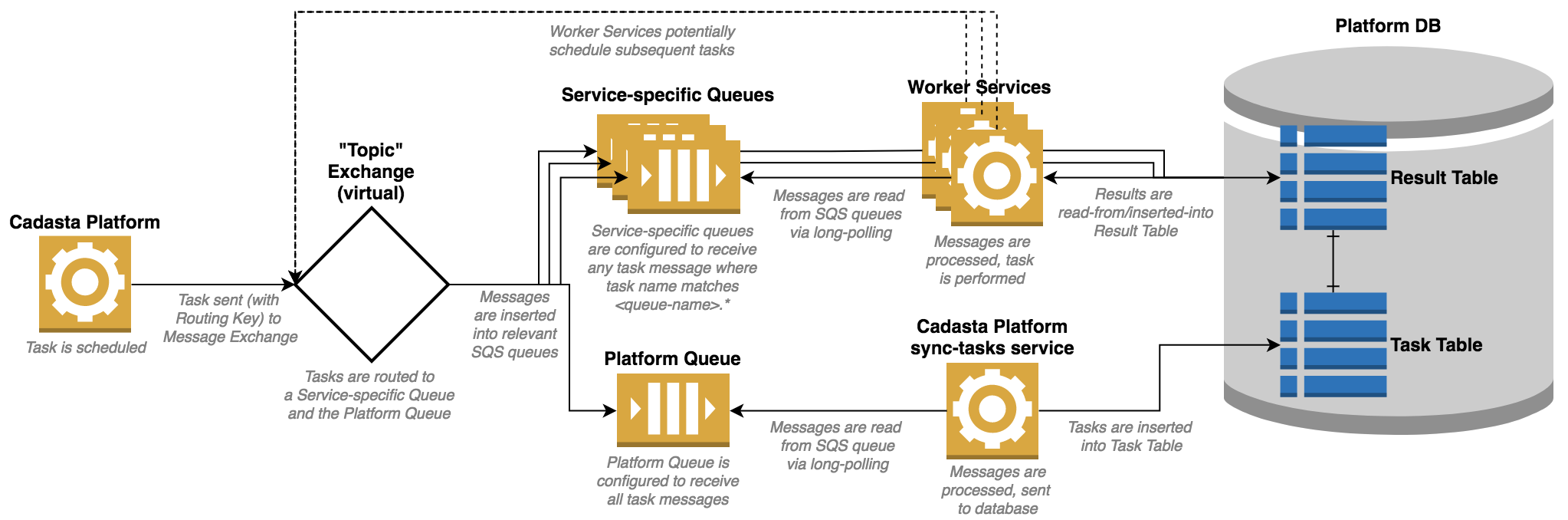
Async System Architecture Diagram
The Cadasta asynchronous system is designed so that both the scheduled tasks and the task results can be tracked by the central Cadasta Platform. To ensure that this takes place, all Celery workers must be correctly configured to support these features.
Tracking Scheduled Tasks
To keep our system aware of all tasks being scheduled, the Cadasta Platform has a process running to consume task messages off of a task-monitor queue and insert those messages into our database. To support this design, all task producers (including worker nodes) must publish their task messages to both the normal destination queues and the task-monitor queue. This is acheived by registering all queues with a Topic Exchange, setting the task-monitor queue to subscribe to all messages sent to the exchange, and setting standard work queues to subscribe to messages with a matching routing_key. Being that the Cadasta Platform is designed to work with Amazon SQS and the SQS backend only keeps exchange/queue declarations in memory, each message producer must have this set up within their configuration.
Tracking Task Results
Tasks results are inserted by each worker into the Platform DB. For this reason, it is important that each worker have network access to the Platform DB (via AWS Security Groups). Additionally, each worker should have a provided username and password that grants them authorization to write to the Platform DB’s Result Table. For reasons of security, it is advised that these credentials be permitted to only access this single table. The Result Table has a one-to-one relation via the task_id column to the Task Table. This should not be enforced via a constraint, as it is possible for a task’s result to be entered into the DB before the sync-tasks service enters the task into the Task Table.
Library
cadasta.workertoolbox.conf.Config
The Config class was built to simplify configuring Celery settings, helping to ensure that all workers adhere to the architecture requirements of the Cadasta asynchronous system. An instance of the Config should come configured with all Celery settings that are required by our system. It is the aim of the class to not require much customization on the part of the developer. However, some customization may be needed when altering configuration between environments (e.g. if dev settings vary greatly from prod settings).
Required Arguments
queues
The only required argument is the queues array. This should contain an array of names for queues that are to be used by the given worker. This includes queues from which the node processes tasks and queues into which the node will schedule tasks. It is not necessary to include the 'celery' or 'platform.fifo' queues, as these will be added automatically. The input of the queues variable will be stored as QUEUES on the Config instance.
Optional Arguments
Any Celery setting may be submitted. It is internal convention that we use the lowercase Celery settings rather than their older upper-case counterparts. This will ensure that they are displayed when calling repr on the Conf instance.
result_backend
Defaults to 'db+postgresql://{0.RESULT_DB_USER}:{0.RESULT_DB_PASS}@{0.RESULT_DB_HOST}/{0.RESULT_DB_NAME}' rendered with self.
broker_transport
Defaults to 'sqs’.
broker_transport_options
Defaults to:
{
'region': 'us-west-2',
'queue_name_prefix': '{}-'.format(QUEUE_NAME_PREFIX)
}task_queues
Defaults to the following set of kombu.Queue objects, where queues is the configuration’s required queues argument and exchange is an a kombu.Exchange object constructed from the task_default_exchange and task_default_exchange_type settings:
set([
Queue('celery', exchange, routing_key='celery'),
Queue(platform_queue, exchange, routing_key='#'),
] + [
Queue(q_name, exchange, routing_key=q_name)
for q_name in queues
])Note: It is recommended that developers not alter this setting.
task_routes
Defaults to a function that will generate a dict with the routing_key matching the first index of the task name split on the . and the exchange set to the _default_exchange_obj.
Note: It is recommended that developers not alter this setting.
task_default_exchange
Defaults to 'task_exchange'
task_default_exchange_type
Defaults to 'topic'
task_track_started
Defaults to True.
Internal Variables
By convention, all variables pertinent to only the Config class (i.e. not used by Celery) should be written entirely uppercase.
PLATFORM_QUEUE_NAME
Defaults to 'platform.fifo'.
Note: It is recommended that developers not alter this setting.
QUEUE_NAME_PREFIX
Used to populate the queue_name_prefix value of the connections broker_transport_options. Defaults to value of QUEUE_PREFIX environment variable if populated, 'dev' if not.
RESULT_DB_USER
Used to populate the default result_backend template. Defaults to RESULT_DB_USER environment variable if populated, 'cadasta' if not.
RESULT_DB_PASS
Used to populate the default result_backend template. Defaults to RESULT_DB_PASS environment variable if populated, 'cadasta' if not.
RESULT_DB_HOST
Used to populate the default result_backend template. Defaults to RESULT_DB_HOST environment variable if populated, 'localhost' if not.
RESULT_DB_PORT
Used to populate the default result_backend template. Defaults to RESULT_DB_PORT environment variable if populated, 'cadasta' if not.
RESULT_DB_NAME
Used to populate the default result_backend template. Defaults to RESULT_DB_PORT environment variable if populated, '5432' if not.
cadasta.workertoolbox.tests.build_functional_tests
When provided with a Celery app instance, this function generates a suite of functional tests to ensure that the provided application’s configuration and functionality conforms with the architecture of the Cadasta asynchronous system.
An example, where an instanciated and configured Celery() app instance exists in a parallel celery module:
from cadasta.workertoolbox.tests import build_functional_tests
from .celery import app
FunctionalTests = build_functional_tests(app)To run these tests, use your standard test runner (e.g. pytest) or call manually from the command-line:
python -m unittest path/to/tests.pyDevelopment
Testing
pip install -r requirements-test.txt
./runtestsDeploying
pip install -r requirements-deploy.txt
python setup.py test clean build publish tagRelease history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
File details
Details for the file cadasta-workertoolbox-0.1.9.tar.gz.
File metadata
- Download URL: cadasta-workertoolbox-0.1.9.tar.gz
- Upload date:
- Size: 8.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | b022290884432984ef9a58eca8346da7e67d40ed5cfb90c9669362f506b8b341 |
|
| MD5 | 7e3fb25566e5ed538b080aea24372b84 |
|
| BLAKE2b-256 | da2cc3e7d95a4511f582b9994383fffddecdbf35074b6c7e7b1d075e051ecc81 |
File details
Details for the file cadasta_workertoolbox-0.1.9-py2.py3-none-any.whl.
File metadata
- Download URL: cadasta_workertoolbox-0.1.9-py2.py3-none-any.whl
- Upload date:
- Size: 12.8 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 45671ce99673a6cbe3cca958faae0f904ebfc173b6461cf52be2420a394ab725 |
|
| MD5 | d8aa0611fc3551733c24ed0f7930fd5b |
|
| BLAKE2b-256 | 908490701137caab516c19821fddb25420c0567fe95e97aa3b625a22217fab07 |







