Climetlab external dataset plugin for the S2S AI competition organised by ECMWF



Project description



S2S AI challenge Datasets
Sub seasonal to Seasonal (S2S) Artificial Intelligence Challenge : https://s2s-ai-challenge.github.io/
In this README is a description of how to get the data for the S2S AI challenge. Here is a more general description of the S2S data. The data used for the S2S AI challenge is a subset of this S2S data.
There are several ways to use the datasets. Either by direct download (wget, curl, browser) for GRIB and NetCDF formats ; or using the climetlab python package with this addon, for GRIB and NetCDF and zarr formats. Zarr is a cloud-friendly experimental data format and supports dowloading only the part of the data that is required. It has been designed to work better than classical format on a cloud environment (experimental).
Datasets description
There are four datasets provided for this challenge. As we are aiming at bringing together the two communities of Machine Learning and Weather Prediction, they have been aliases to use both two points of views :
| ML | NWP | |
|---|---|---|
training-input |
hindcast-input |
Training dataset (input for training the ML models) |
training-output-reference |
hindcast-like-observations |
Training dataset (output for training the ML models) |
test-input |
forecast-input |
Test dataset (DO NOT use) |
test-output-reference |
forecast-like-observations |
Test dataset (DO NOT use) |
test-output-benchmark |
forecast-benchmark |
Benchmark output (on the test dataset) (NOT AVAILABLE) |
Overfitting is always an potential issue when using ML algorithms. To address this, the data is usually split into three datasets :
training,
validation
and test.
This terminology has lead to some confusion in the past.
Splitting the hindcast-input (training-input) dataset between training and validation is standard way and should be decided carefully.
The forecast-input (test-input) must not be used as a validation dataset : it must not be used to tune the hyperparameters or make decision about the ML model.
Fostering discussions about how to prevent overfitting may be an outcome of the challenge.
Hindcast input (Training input)
The hindcast-input(training-input) dataset consists in data from three different models : ECMWF (ecmf), ECCC (cwao), NCEP (kwbc).
These data are hindcast data. This is used as the input for training the ML models.
This dataset is available as grib, netcdf or zarr.
In this dataset, the data is available from 1998 for the oldest, to 2019/12/31 for the most recent.
- ECMWF hindcast data
- forecast_time : from 2000/01/01 to 2019/12/31, weekly every 7 days (every Thurday).
- lead_time : 0 to 46 days
- valid_time (forecast_time + lead_time): from 2000/01/01 to 2019/12/31
- ECCC hindcast data
- forecast_time : from , weekly every 7 days (every Thurday).
- lead_time : 1 to 32 days
- valid_time (forecast_time + lead_time): from
- variables sm20, sm100, st20, st100 not available
- NCEP hindcast data
- forecast_time : from 1999/01/07 to 2010/12/30, weekly every 7 days (every Thurday).
- lead_time : 1 to 44 days
- valid_time (forecast_time + lead_time): from 1999/01/07 to 2011/02/11
- variable "rsn" not available.
List of files : grib, netcdf, zarr
Forecast input (Test input)
The forecast-input (test-input) dataset consists also in data from three different models : ECMWF (ecmf), ECCC (cwao), NCEP (eccc), for different dates.
These data are forecast data.
This could be used the input for applying the ML models in order to generate the output which is submitted for the challenge.
Using data from earlier date that 2020/01/01 is also allowed during the prediction phase.
The forecast start dates in this dataset are from 2020/01/02 to 2020/12/31.
- For all 3 models :
- forecast_time : from 2020/01/02 to 2020/12/31, weekly every 7 days (every Thurday).
- valid_time (forecast_time + lead_time): from 2020/01/02 to 2020/12/31
- ECMWF forecast
- lead_time : 0 to 46 days
- ECCC forecast
- lead_time : 1 to 32 days
- variables sm20, sm100, st20, st100 not available
- NCEP forecast
- lead_time : 1 to 44 days
- variable "rsn" not available.
List of files : grib, netcdf, zarr
Observations
The hindcast-like-observations (training-output-reference) dataset.
The forecast-like-observations (test-output-reference) dataset.
The observations are the ground truth to compare with the ML model output and evaluate them. It consists in observation from instruments of temperature and accumulated total precipitation. (TODO add more descriptions) (point to the scripts to create them ? TODO). Generally speaking, only past data can be used by the ML models to perform their forecast :
Rule 1 : Observed data beyond the forecast date should not be used for prediction, for instance a forecast starting on 2020/07/01 should not use observed data beyond 2020/07/01).
Dates in the observation dataset are from 2000/01/01 to 2021/02/20. (TODO check dates)
The observations dataset have been build from real instrument observations.
- The
hindcast-like-observations(training-output-reference) dataset : - Available from 2000/01/01 to 2019/12/31, weekly every 7 days (every Thurday)
- Observation data before 2019/12/31 can be used for training (as the truth to evaluate and optimize the ML models or tweak hyper parameters using train/valid split or cross-validation).
- The
forecast-like-observations(test-output-reference) dataset. - Available from2020/01/01 to 2021/02/20 , weekly every 7 days (every Thurday)
- The test data must not be used during training. In theory, these data should not be disclosed during the challenge, but the nature of the data make is possible to access it from other sources. That is the reason why the code used for training model must be submitted along with the prediction (as a jupyter notebook) and the top ranked proposition will be reviewed by the organizing board.
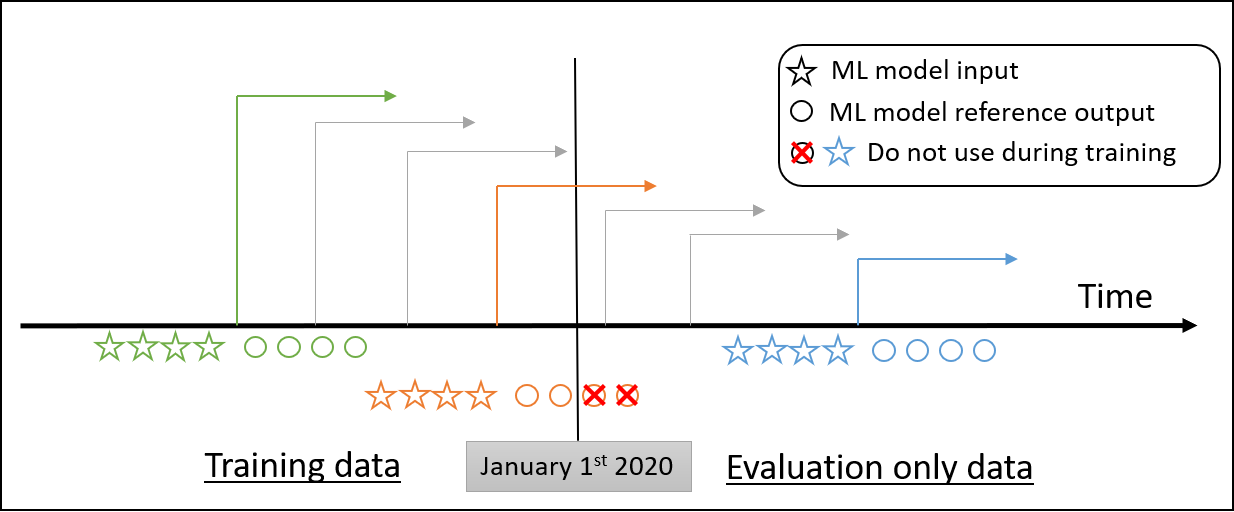
During forecast phase (i.e. the evaluation phase using the forecast-input dataset), 2020 observation data is used. Rule 1 still stands : Observed data beyond the forecast start date should not be used for prediction.
Forecast Benchmark (Test output benchmark) (Not yet available)
The forecast-benchmark (test-output-benchmark) dataset is an example of output of a ML model to be submitted.
The "ML model" used to produce this dataset is TODO. It consists in applying to the `forecast-input' a simple re-calibration of from the mean of the hindcast (training) data.
- forecast_time : from 2020/01/01 to 2020/12/31, weekly every 7 days (every Thurday).
- lead_time : two values : 28 days and 35 days (To be discussed)
- valid_time (forecast_time + lead_time): from 2020/01/01 to 2020/12/31
Data download (GRIB or NetCDF)
The list of GRIB and files for the 'training-input' dataset can be found at :
List of files GRIB files :https://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/training-input/0.3.0/grib/index.html,
List of files NetCDF files : https://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/training-input/0.3.0/netcdf/index.html,
For input datasets, the pattern is https://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/{datasetname}/0.3.0/{format}/{origin}-{fctype}-{parameter}-YYYYMMDD.grib
For observations datasets, the pattern is https://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/{datasetname}/{parameter}/{frequency}-since-2000/YYYYMMDD.nc
The URLs are constructed according to the following pattern:
- {datasetname} : training-input. In the URLs the dataset name must follow the ML naming (training-input, test-input)
- {origin} : ecmwf or eccc or ncep.
- {fctype} : hindcast (training dataset and forecast for test dataset).
- {parameter} is "t2m" for surface temperature at 2m, "tp" for total precipitation using CF convention.
- YYYYMMDD is the date of main forecast time in the file.
- frequency is "weekly" ("daily" for test dataset)
Example to retrieve the file with wget :
wget https://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/training-input/0.3.0/grib/ncep-hindcast-q-20101014.grib (132.8M )
Zarr format (experimental).
The zarr storage location include all the reference data. The zarr urls are not designed to be open in a browser (see zarr): While accessing the zarr storage without climetlab may be possible, we recommend using climetlab with the appropriate plugin (climetlab-s2s-ai-challenge)
Zarr urls are :
training-inputhttps://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/training-input/{origin}/0.1.43/zarr/ (TODO not yet available)training-output-reference: not available.forecast-benchmark: not available.
Using climetlab to access the data (supports grib, netcdf and zarr)
See the demo notebooks here (https://github.com/ecmwf-lab/climetlab-s2s-ai-challenge/notebooks) :
- Netcdf nbviewer colab
- Grib nbviewer colab
- Zarr nbviewer colab (experimental). (TODO update this notebook)
The climetlab python package allows easy access to the data with a few lines of code such as:
Full data not uploaded. Only two dates available for now.
!pip install climetlab climetlab_s2s_ai_challenge
import climetlab as cml
ds = cml.load_dataset("s2s-ai-challenge-training-input", origin="ecmwf", date="20200102", parameter='t2m')
ds.to_xarray()
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file climetlab-s2s-ai-challenge-0.5.0.tar.gz.
File metadata
- Download URL: climetlab-s2s-ai-challenge-0.5.0.tar.gz
- Upload date:
- Size: 18.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/4.0.1 pkginfo/1.7.0 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.61.0 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | c81f82dd9ec838d12a86d732d6c9fe3b89faf1f5cf01376d29d874611394cb34 |
|
| MD5 | 95fed43cfbcfc62478ac1ee863efcda1 |
|
| BLAKE2b-256 | 715d043dadb28814ecf18120cc6caf459acffb4cf553642800ba2310a20bb904 |







