Climetlab external dataset plugin for the S2S AI competition organised by ECMWF



Project description



S2S AI challenge Datasets
This is a climetlab plugin for Sub-seasonal to Seasonal (S2S) Artificial Intelligence Challenge: https://s2s-ai-challenge.github.io/.
In this README is a description of how to get the data for the S2S AI challenge. Here is a more general description of the S2S data. The data used for the S2S AI challenge is a subset of the S2S data library. More detail can be found at https://confluence.ecmwf.int/display/S2S and https://confluence.ecmwf.int/display/S2S/Parameters.
There are several ways to use the datasets. Either by direct download (wget, curl, browser) for GRIB and NetCDF formats; or using the climetlab python package with this addon, for GRIB and NetCDF and zarr formats. zarr is a cloud-friendly experimental data format and supports dowloading only the part of the data that is required. It has been designed to work better than classical format on a cloud environment (experimental).
Installation
pip install -U climetlab climetlab_s2s_ai_challenge
API
import climetlab
Use climetlab.load_dataset('s2s-ai-challenge-{datasetname}') with the following keywords:
datasetname: name of the dataset, see dataset descriptionparameter: variable, see hindcast input for the different modelsorigin: name of the model [ecmwf,eccc,ncep] or modelling center [ecmf,cwao,kwbc]. Provideoriginonly fortraining/test-input/hindcast/forecast-input.date:YYYYMMDDis the date of the 2020 forecast fortest-input/forecast-input. The same dates are required for the on-the-flytraining-input/hindcast-inputbut returns the multi-year hindcast for the givenMMDDdate. Please provideint,str,np.datetimeor list of the former in formatYYYYMMDDD. Providing nodatekeyword downloads all dates.format: data format, choose from [netcdf(always available),grb(only forinput-*),zarr(experimental)]
Coordinates
Overview of the time-related coordinates.
name |
CF convention standard_name |
description | comment |
|---|---|---|---|
forecast_time |
forecast_reference_time | The forecast reference time in NWP is the "data time", the time of the analysis from which the forecast was made. It is not the time for which the forecast is valid. | |
lead_time |
forecast_period | Forecast period is the time interval between the forecast reference time and the validity time. | |
valid_time |
time | time for which the forecast is valid | forecast_time + lead_time |
All datasets are on a global 1.5 degree grid.
Parameter
parameter describes the variable to download. The most important two variables for the s2s-ai-challenge are the two target variables t2m and tp:
| parameter | long_name | standard_name | unit | description & aggregation type | week 3-4 aggregation | week 5-6 aggregation | link to source |
|---|---|---|---|---|---|---|---|
t2m |
2m temperature | air_temperature | K | Temperature at 2m height averaged for the date given | average [day 14, day 27] | average [day 28, day 41] | model, observations |
tp |
total precipitation | precipitation_amount | kg m-2 | Total precipitation accumulated from forecast_time until including valid_time, e.g. lead_time = 1 days accumulates precipitation_flux pr from 6-hourly steps 0,6,12,18 at date forecast_time |
day 28 minus day 14 | day 42 minus day 28 | model |
pr |
precipitation flux | precipitation_flux | kg m-2 | Precipitation accumulated for the date given | use tp |
use tp |
observations |
Given the different nature of the parameters, with forecast_time Jan 2nd 2020, tp lead_time=1 days and t2m lead_time=0 days describe both the weather of Jan 2nd 2020, as tp is aggregated pr from Jan 2nd 00:00 to Jan 3rd 00:00 and t2m as the average of Jan 2nd. Furthermore tp is aggregated since forecast_time, i.e. tp lead_time=5 days is pr aggregated from Jan 2nd 00:00 to Jan 7th 00:00.
For the remaining variable descriptions, see ECWMF S2S description.
Datasets description
There are four datasets provided for this challenge. As we are aiming at bringing together the two communities of Machine Learning and Weather Prediction, they have been aliases to use both two points of views:
| ML | NWP | |
|---|---|---|
training-input |
hindcast-input |
Training dataset (input for training the ML models) |
training-output-reference |
hindcast-like-observations |
Training dataset (output for training the ML models) |
training-output-benchmark |
hindcast-benchmark |
Benchmark output (on the training dataset) |
test-input |
forecast-input |
Test dataset (DO NOT use for training) |
test-output-reference |
forecast-like-observations |
Test dataset (DO NOT use) |
test-output-benchmark |
forecast-benchmark |
Benchmark output (on the test dataset) |
observations |
observations |
Observations with time dimension |
Overfitting is always an potential issue when using ML algorithms. To address this, the data is usually split into three datasets :
training,
validation
and test.
This terminology has lead to some confusion in the past.
Splitting the hindcast-input (training-input) dataset between training and validation is standard way and should be decided carefully.
The forecast-input (test-input) must not be used as a validation dataset: it must not be used to tune the hyperparameters or make decision about the ML model.
Hindcast input
These data are hindcast data. This is used as the input for training the ML models.
The hindcast-input(training-input) dataset consists of data from three different models/centers:
| center name | model name |
|---|---|
| ecmwf | ecmf |
| eccc | cwao |
| ncep | kwbc |
Use either origin="ecmf" (model name) or origin="ecmwf" (center name).
This dataset is available as format: grib, netcdf or zarr.
- ECMWF hindcast data
forecast_time: from 2000/01/02 to 2019/12/31, corresponding to the weekly Thurdays in 2020.lead_time: 0 to 46 daysvalid_time(forecast_time+lead_time): from 2000/01/02 to 2020/02/13- availables parameters :
t2m(2t)/siconc(ci)/gh/lsm/msl/q/rsn/sm100/sm20/sp/sst/st100/st20/t/tcc/tcw/tp/ttr/u/v(differing name in MARS database)
- ECCC hindcast data
forecast_time: from 2000/01/02 to 2019/12/31, corresponding to the weekly Thurdays in 2020.lead_time: 1 to 32 daysvalid_time(forecast_time + lead_time): from 2000/01/03 to 2020/02/01- availables parameters:
t2m(2t)/siconc(ci)/gh/lsm/msl/q/rsn/sp/sst/t/tcc/tcw/tp/ttr/u/v(differing name in MARS database) - parameters not available:
sm20/sm100/st20/st100
- NCEP hindcast data
forecast_time: from 1999/01/07 to 2010/12/30, corresponding to the weekly Thurdays in 2010, see Vitart et al. 2017, NCEP hindcast dates differ from ECMWF and ECCC hindcastslead_time: 1 to 44 daysvalid_time(forecast_time+lead_time): from 1999/01/07 to 2011/02/11- availables parameters:
t2m(2t)/siconc(ci)/gh/lsm/msl/q/sm100/sm20/sp/sst/st100/st20/t/tcc/tcw/tp/ttr/u/v(differing name in MARS database) - parameter not available:
rsn
hindcast = climetlab.load_dataset('s2s-ai-challenge-training-input', date=[20200102], origin='ecwmf', parameter='tp', format='netcdf').to_xarray()
hindcast.coords
Coordinates:
* realization (realization) int64 0 1 2 3 4 5 6 7 8 9 10
* forecast_time (forecast_time) datetime64[ns] 2000-01-02 ... 2019-01-02
* lead_time (lead_time) timedelta64[ns] 0 days 1 days ... 45 days 46 days
* latitude (latitude) float64 90.0 88.5 87.0 85.5 ... -87.0 -88.5 -90.0
* longitude (longitude) float64 0.0 1.5 3.0 4.5 ... 355.5 357.0 358.5
valid_time (forecast_time, lead_time) datetime64[ns] 2000-01-02 ... 2...
# for ncep hindcast provide 2010 date strings
hindcast_ncep = climetlab.load_dataset('s2s-ai-challenge-training-input', date=[20100107], origin='ncep', parameter='tp', format='netcdf').to_xarray()
hindcast_ncep.coords
Coordinates:
* realization (realization) int64 0 1 2 3
* forecast_time (forecast_time) datetime64[ns] 1999-01-07 ... 2010-01-07
* lead_time (lead_time) timedelta64[ns] 1 days 2 days ... 43 days 44 days
* latitude (latitude) float64 90.0 88.5 87.0 85.5 ... -87.0 -88.5 -90.0
* longitude (longitude) float64 0.0 1.5 3.0 4.5 ... 355.5 357.0 358.5
valid_time (forecast_time, lead_time) datetime64[ns] 1999-01-08 ... 2...
List of files : grib, netcdf, zarr (not available)
Forecast input
The forecast-input (test-input) dataset consists also in data from three different models: ECMWF (ecmf), ECCC (cwao), NCEP (eccc), for different dates.
These data are forecast data.
This could be used the input for applying the ML models in order to generate the output which is submitted for the challenge.
- For all 3 models:
forecast_time: from 2020/01/02 to 2020/12/31, weekly every Thurday in 2020.valid_time(forecast_time+lead_time): from 2020/01/02 to 2021/02/xx- available parameters (same as for hindcast input (training input)
- ECMWF forecast
lead_time: 0 to 46 days
- ECCC forecast
lead_time: 1 to 32 days
- NCEP forecast
lead_time: 1 to 44 days
forecast = climetlab.load_dataset('s2s-ai-challenge-test-input', date=[20200102], origin='ecmwf', parameter='tp', format='netcdf').to_xarray()
forecast.coords
Coordinates:
* realization (realization) int64 0 1 2 3 4 5 6 7 ... 44 45 46 47 48 49 50
* forecast_time (forecast_time) datetime64[ns] 2020-01-02
* lead_time (lead_time) timedelta64[ns] 0 days 1 days ... 45 days 46 days
* latitude (latitude) float64 90.0 88.5 87.0 85.5 ... -87.0 -88.5 -90.0
* longitude (longitude) float64 0.0 1.5 3.0 4.5 ... 355.5 357.0 358.5
valid_time (forecast_time, lead_time) datetime64[ns] 2020-01-02 ... 2...
List of files : grib, netcdf, zarr (missing)
Observations (Reference Output)
The hindcast-like-observations (training-output-reference) dataset matches the training-input of the ECMWF and ECCC model.
The forecast-like-observations (test-output-reference) dataset matches the test-input of all three models.
The observations are the ground truth to compare with the ML model output and evaluate them. It consists in observations from instruments of temperature and accumulated total precipitation. The NOAA CPC datasets were downloaded from IRIDL. We provide observations in the same dimensions as the forecasts/hindcasts to have an easy match of forecasts/hindcast and ground truth. See the script for technical details.
These observations are the ground truth and do not correspond to a model. The format is always netcdf.
hindcast_like_obs = climetlab.load_dataset('s2s-ai-challenge-training-output-reference', date=[20200102], parameter='tp').to_xarray() # origin and format not accepted
hindcast_like_obs.coords
Coordinates:
* latitude (latitude) float64 90.0 88.5 87.0 85.5 ... -87.0 -88.5 -90.0
* longitude (longitude) float64 0.0 1.5 3.0 4.5 ... 355.5 357.0 358.5
* forecast_time (forecast_time) datetime64[ns] 2000-01-02 ... 2019-01-02
* lead_time (lead_time) timedelta64[ns] 0 days 1 days ... 45 days 46 days
valid_time (lead_time, forecast_time) datetime64[ns] 2000-01-02 ... 2...
forecast_like_obs = climetlab.load_dataset('s2s-ai-challenge-test-output-reference', date=[20200102], parameter='tp').to_xarray() # origin and format not accepted
forecast_like_obs.coords
Coordinates:
* latitude (latitude) float64 90.0 88.5 87.0 85.5 ... -87.0 -88.5 -90.0
* longitude (longitude) float64 0.0 1.5 3.0 4.5 ... 355.5 357.0 358.5
* forecast_time (forecast_time) datetime64[ns] 2020-01-02
* lead_time (lead_time) timedelta64[ns] 0 days 1 days ... 45 days 46 days
valid_time (lead_time, forecast_time) datetime64[ns] 2020-01-02 ... 2...
In case you want to train on the NCEP hindcast, which has forecast_times from 1999 to 2010, please use download observations with a time dimension s2s-ai-challenge-observations and use climetlab_s2s_ai_challenge.extra.forecast_like_observations to match observations to the corresponding valid_times of the forecast/hindcast.
obs_time = climetlab.load_dataset('s2s-ai-challenge-observations', parameter=['pr', 't2m']).to_xarray()
# equivalent
obs_lead_time_forecast_time = climetlab.load_dataset('s2s-ai-challenge-observations', parameter=['pr', 't2m']).to_xarray(like=hindcast_ncep)
obs_lead_time_forecast_time = climetlab_s2s_ai_challenge.extra.forecast_like_observations(hindcast_ncep, obs_time)
obs_lead_time_forecast_time.coords
<xarray.Dataset>
Dimensions: (forecast_time: 12, latitude: 121, lead_time: 44, longitude: 240)
Coordinates:
valid_time (forecast_time, lead_time) datetime64[ns] 1999-01-08 ... 2...
* latitude (latitude) float64 90.0 88.5 87.0 85.5 ... -87.0 -88.5 -90.0
* longitude (longitude) float64 0.0 1.5 3.0 4.5 ... 355.5 357.0 358.5
* forecast_time (forecast_time) datetime64[ns] 1999-01-07 ... 2010-01-07
* lead_time (lead_time) timedelta64[ns] 1 days 2 days ... 43 days 44 days
This function can be used for all initialized hindcasts and forecasts from the SubX and S2S projects. Beware of the different starting dates of 2020 forecasts when using them for the s2s-ai-challenge. Observations from NOAA CPC are regridded conservatively with xesmf to the S2S 1.5 deg grid. The original 0.5 degree spatial resolution raw observations can be obtained via grid='720x360'.
Generally speaking, only data available when the forecast is issued can be used by the ML models to perform their forecast:
Rule: Observed data beyond the forecast date should not be used for prediction, for instance a forecast starting on 2020/07/01 should not use observed data beyond 2020/07/01).
For all rules, see the challenge website.
See also the general rules of the challenge here.
Dates in the observation dataset are from 2000/01/01 to 2021/02/15.
The observations dataset have been build from real instrument observations.
- The
hindcast-like-observations(training-output-reference) dataset : - Available from 2000/01/01 to 2019/12/31, weekly every 7 days (every Thurday)
- Observation data before 2019/12/31 can be used for training (as the truth to evaluate and optimize the ML models or tweak hyper parameters using train/valid split or cross-validation).
- The
forecast-like-observations(test-output-reference) dataset. - Available from 2020/01/01 to 2021/02/20 , weekly every 7 days (every Thurday)
- The test data must not be used during training. In theory, these data should not be disclosed during the challenge, but the nature of the data make is possible to access it from other sources. That is the reason why the code used for training model must be submitted along with the prediction (as a jupyter notebook) and the top ranked proposition will be reviewed by the organizing board.
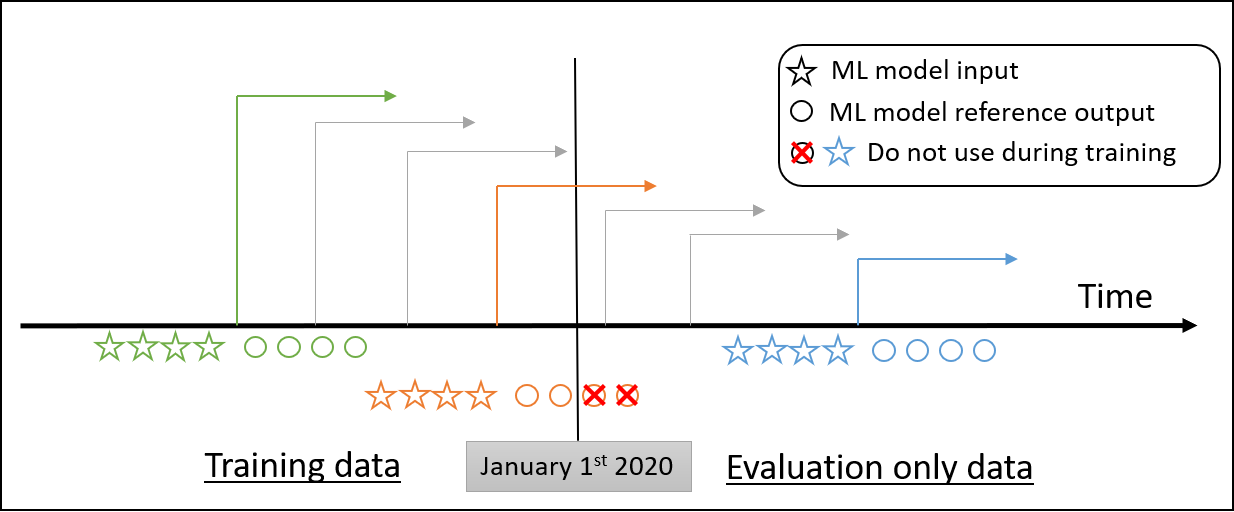
During forecast phase (i.e. the evaluation phase using the forecast-input dataset), 2020 observation data is used. Rule 1 still stands: Observed data beyond the forecast start date should not be used for prediction.
Forecast Benchmark (Benchmark output)
The forecast-benchmark (test-output-benchmark) dataset is a probabilistic re-calibrated ECMWF forecast with categories below normal, near normal, above normal. The calibration has been performed by using the tercile boundaries from the model climatology rather than from observations.
The benchmark data is available as follows:
forecast_time: from 2020/01/02 to 2020/12/31, weekly every 7 days (every Thurday).lead_time: 14 days and 28 days, where this day represents the first day of the biweekly aggregatevalid_time(forecast_time+lead_time): from 2020/01/01 to 2021/01/29category:'below normal','near normal','above normal'
bench = climetlab.load_dataset('s2s-ai-challenge-training-output-benchmark', parameter='tp').to_xarray() # origin, date and format not accepted
bench.coords
Coordinates:
* category (category) object 'below normal' 'near normal' 'above normal'
* forecast_time (forecast_time) datetime64[ns] 2000-01-02 ... 2019-12-31
* lead_time (lead_time) timedelta64[ns] 14 days 28 days
* latitude (latitude) float64 90.0 88.5 87.0 85.5 ... -87.0 -88.5 -90.0
* longitude (longitude) float64 0.0 1.5 3.0 4.5 ... 355.5 357.0 358.5
valid_time (forecast_time, lead_time) datetime64[ns] 2000-01-16 ... 2...
bench = climetlab.load_dataset('s2s-ai-challenge-test-output-benchmark', parameter='tp').to_xarray() # origin, date and format not accepted
bench.coords
Coordinates:
* category (category) object 'below normal' 'near normal' 'above normal'
* forecast_time (forecast_time) datetime64[ns] 2020-01-02 ... 2020-12-31
* lead_time (lead_time) timedelta64[ns] 14 days 28 days
* latitude (latitude) float64 90.0 88.5 87.0 85.5 ... -87.0 -88.5 -90.0
* longitude (longitude) float64 0.0 1.5 3.0 4.5 ... 355.5 357.0 358.5
valid_time (forecast_time, lead_time) datetime64[ns] 2020-01-16 ... 2...
Observations
For other initialized forecasts, you can download observations for parameters t2m and pr with a time dimension corresponding to valid_time. These are then used to create observations formatted like initialized forecasts/hindcasts locally. Observations are available from 1999 to 2021. See parameter for description.
climetlab_s2s_ai_challenge.extra.forecast_like_observations matches observations to the corresponding valid_times of the forecast/hindcast.
forecast = climetlab.load_dataset('s2s-ai-challenge-training-input',
date=20100107, origin='ncep', parameter='tp',
format='netcdf').to_xarray()
obs_lead_time_forecast_time = climetlab.load_dataset('s2s-ai-challenge-observations', parameter=['pr', 't2m']).to_xarray(like=forecast)
# equivalent
obs_time = climetlab.load_dataset('s2s-ai-challenge-observations', parameter=['pr', 't2m']).to_xarray()
obs_time.coords
Coordinates:
* time (time) datetime64[ns] 1999-01-01 1999-01-02 ... 2021-04-29
* latitude (latitude) float64 90.0 88.5 87.0 85.5 ... -87.0 -88.5 -90.0
* longitude (longitude) float64 0.0 1.5 3.0 4.5 ... 354.0 355.5 357.0 358.5
obs_lead_time_forecast_time = climetlab_s2s_ai_challenge.extra.forecast_like_observations(forecast, obs_time)
obs_lead_time_forecast_time
<xarray.Dataset>
Dimensions: (forecast_time: 12, latitude: 121, lead_time: 44, longitude: 240)
Coordinates:
valid_time (forecast_time, lead_time) datetime64[ns] 1999-01-08 ... 2...
* latitude (latitude) float64 90.0 88.5 87.0 85.5 ... -87.0 -88.5 -90.0
* longitude (longitude) float64 0.0 1.5 3.0 4.5 ... 355.5 357.0 358.5
* forecast_time (forecast_time) datetime64[ns] 1999-01-07 ... 2010-01-07
* lead_time (lead_time) timedelta64[ns] 1 days 2 days ... 43 days 44 days
Data variables:
t2m (forecast_time, lead_time, latitude, longitude) float32 ...
tp (forecast_time, lead_time, latitude, longitude) float32 na...
Attributes:
script: climetlab_s2s_ai_challenge.extra.forecast_like_observations
Data download (GRIB or NetCDF)
The URLs to download the data are constructed according to the following patterns:
For input datasets, the pattern is https://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/{datasetname}/0.3.0/{format}/{origin}-{fctype}-{parameter}-YYYYMMDD.nc
For observations datasets (reference output), the pattern is https://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/{datasetname}/{parameter}-YYYYMMDD.nc
For benchmark datasets, the pattern will be similar to https://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/training-output-benchmark/{parameter}.nc
- {datasetname} : In the URLs the dataset name must follow the ML naming (
training-inputortraining-output-referenceortraining-output-benchmark). - {format} is
netcdf. Training output is also available as GRIB file, usingformat='grib'and replacing".nc"by".grib" - {fctype}:
hindcastfor training orforecastfor test - {parameter} is
t2mfor surface temperature at 2m,tpfor total precipitation - {origin} :
ecmwforecccorncep - {weeks} from [
"34","56",["34", "56"]] only forbenchmark - {grid} from [
"240x121"(default),"720x360"] only forobservations YYYYMMDDis the date of the 2020 forecast fortest-input/forecast-input. The same dates are required for the on-the-flytraining-input/hindcast-inputbut return the multi-year hindcast for thatMMDD.
The list of files for the training-input dataset can be found at
- GRIB: https://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/training-input/0.3.0/grib/index.html,
- NetCDF: https://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/training-input/0.3.0/netcdf/index.html,
The list of files for the training-output-benchmark dataset can be found at https://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/training-output-benchmark/index.html (NetCDF only)
The list of files for the training-output-reference dataset can be found at https://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/training-output-reference/index.html (NetCDF only)
Example to retrieve the file with wget :
wget https://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/training-input/0.3.0/grib/ncep-hindcast-q-20101014.grib (132.8M )
Zarr format (experimental).
The zarr storage location include all the reference data. The zarr urls are not designed to be open in a browser (see zarr): While accessing the zarr storage without climetlab may be possible, we recommend using climetlab with the appropriate plugin (climetlab-s2s-ai-challenge)
Zarr urls are:
training-inputhttps://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/training-input/{origin}/0.3.0/zarr/ (Not fully yet available)training-output-referencehttps://storage.ecmwf.europeanweather.cloud/s2s-ai-challenge/data/training-output-reference/{origin}/0.3.0/zarr/ (Not full yet available)
Using climetlab to access the data (supports grib, netcdf and zarr)
The climetlab python package allows easy access to the data with a few lines of code such as:
!pip install climetlab climetlab_s2s_ai_challenge
import climetlab as cml
cml.load_dataset("s2s-ai-challenge-training-input",
origin='ecmwf',
date=[20200102,20200109],
# optional : format='grib'
parameter='tp').to_xarray()
cml.load_dataset("s2s-ai-challenge-training-output-reference",
date=[20200102,20200109],
parameter='tp').to_xarray()
See the demo notebooks here: https://github.com/ecmwf-lab/climetlab-s2s-ai-challenge/notebooks.
Accessing the training data :
Getting the observation (reference output) dataset see the demo_observations notebook.
Getting the benchmark dataset see the demo_benchmark notebook.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file climetlab-s2s-ai-challenge-0.8.2.tar.gz.
File metadata
- Download URL: climetlab-s2s-ai-challenge-0.8.2.tar.gz
- Upload date:
- Size: 34.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.0 CPython/3.8.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | e69a449558985ed330954b141354b98310903eda03457205c4650154d7a4aef0 |
|
| MD5 | bbd52ec3aedfae30d1e2af50f99e12df |
|
| BLAKE2b-256 | d691479ec395eee49a88acf311eaa77b7dd520ecea07d07043384274fb7b3edb |







