Deep Insight And Neural Network Analysis


Project description







Deep Insight And Neural Network Analysis
DIANNA is a Python package that brings explainable AI (XAI) to your research project. It wraps carefully selected XAI methods in a simple, uniform interface. It's built by, with and for (academic) researchers and research software engineers working on machine learning projects.
Why DIANNA?
DIANNA software is addressing needs of both (X)AI researchers and mostly the various domains scientists who are using or will use AI models for their research without being experts in (X)AI. DIANNA is future-proof: one of the very few XAI library supporting the Open Neural Network Exchange (ONNX) format.
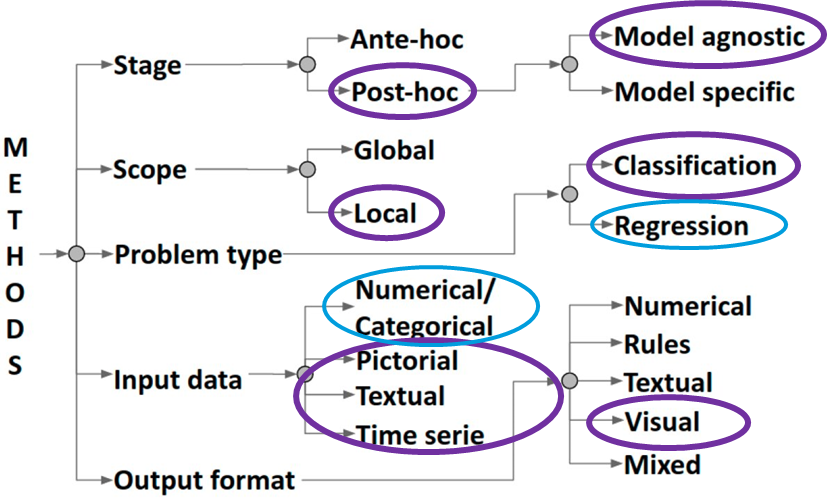
After studying the vast XAI landscape we have made choices in the parts of the XAI Taxonomy on which methods, data modalities and problems types to focus. Our choices, based on the largest usage in scientific literature, are shown graphically in the XAI taxonomy below:
The key points of DIANNA:
- Provides an easy-to-use interface for non (X)AI experts
- Implements well-known XAI methods LIME, RISE and KernelSHAP, chosen by systematic and objective evaluation criteria
- Supports the de-facto standard of neural network models - ONNX
- Supports images, text, time series, and tabular data modalities, embeddings are currently being developed
- Comes with simple intuitive image, text, time series, and tabular benchmarks, so can help you with your XAI research
- Includes scientific use-cases tutorials
- Easily extendable to other XAI methods
For more information on the unique strengths of DIANNA with comparison to other tools, please see the context landscape.
Installation


DIANNA can be installed from PyPI using pip on any of the supported Python versions (see badge):
python3 -m pip install dianna
To install the most recent development version directly from the GitHub repository run:
python3 -m pip install git+https://github.com/dianna-ai/dianna.git
If you get an error related to OpenMP when importing dianna, have a look at this issue for possible workarounds.
Pre-requisites only for Macbook Pro with M1 Pro chip users
- To install TensorFlow you can follow this tutorial.
- To install TensorFlow Addons you can follow these steps. For further reading see this issue. Note that this temporary solution works only for macOS versions >= 12.0. Note that this step may have changed already, see https://github.com/dianna-ai/dianna/issues/245.
- Before installing DIANNA, comment
tensorflowrequirement insetup.cfgfile (tensorflow package for M1 is calledtensorflow-macos).
Getting started
You need:
- your trained ONNX model (convert my pytorch/tensorflow/keras/scikit-learn model to ONNX)
- a data item to be explained
You get:
- a relevance map overlayed over the data item
Template example for any data modality and explainer
- Provide your trained model and data item ( text, image, time series or tabular )
model_path = 'your_model.onnx' # model trained on your data modality
data_item = <data_item> # data item for which the model's prediction needs to be explained
- If the task is classification: which are the classes your model has been trained for?
labels = [class_a, class_b] # example of binary classification labels
Which of these classes do you want an explanation for?
explained_class_index = labels.index(<explained_class>) # explained_class can be any of the labels
- Run dianna with the explainer of your choice ( 'LIME', 'RISE' or 'KernalSHAP') and visualize the output:
explanation = dianna.<explanation_function>(model_path, data_item, explainer)
dianna.visualization.<visualization_function>(explanation[explained_class_index], data_item)
Text and image usage
Examples
Lets illustrate the template above with *textual* data. The data item of interest is a sentence being (a part of) a movie review and the model has been trained to classify reviews into positive and negative sentiment classes. We are intersted which words are contributing positively (red) and which - negatively (blue) towards the model's desicion to classify the review as positive and we would like to use the *LIME* explainer:
model_path = 'your_text_model.onnx'
# also define a model runner here (details in dedicated notebook)
review = 'The movie started great but the ending is boring and unoriginal.'
labels = ["negative", "positive"]
explained_class_index = labels.index("positive")
explanation = dianna.explain_text(model_path, text, 'LIME')
dianna.visualization.highlight_text(explanation[explained_class_index], model_runner.tokenizer.tokenize(review))

Here is another illustration on how to use dianna to explain which parts of a bee image contributied positively (red) or negativey (blue) towards a classifying the image as a 'bee' using RISE.
The Imagenet model has been trained to distinguish between 1000 classes (specified in labels).
For images, which are data of higher dimention compared to text, there are also some specifics to consider:
model_path = 'your_image_model.onnx'
image = PIL.Image.open('your_bee_image.jpeg')
axis_labels = {2: 'channels'}
explained_class_index = labels.index('bee')
explanation = dianna.explain_image(model_path, image, 'RISE', axis_labels=axis_labels, labels=labels)
dianna.visualization.plot_image(explanation[explained_class_index], utils.img_to_array(image)/255., heatmap_cmap='bwr')
plt.show()

And why would Imagenet think the same image would be a garden spider?
explained_class_index = labels.index('garden_spider') # interested in the image being classified as a garden spider
explanation = dianna.explain_image(model_path, image, 'RISE', axis_labels=axis_labels, labels=labels)
dianna.visualization.plot_image(explanation[explained_class_index], utils.img_to_array(image)/255., heatmap_cmap='bwr')
plt.show()

Overview tutorial
There are full working examples on how to use the supported explainers and how to use dianna for all supported data modalities in our overview tutorial.
IMPORTANT: Sensitivity to hyperparameters
The explainers are sensitive to the choice of their hyperparameters! In this work, this sensitivity to hyperparameters is researched and useful conclusions are drawn. The default hyperparameters used in DIANNA for each explainer as well as the values for our tutorial examples are given in the Tutorials README.
Introductory video
This video shows the main functionality of DIANNA and shows you how to use DIANNA also from its dashboard.

Dashboard
Explore the explanations of your trained model using the DIANNA dashboard. Click here for more information.
Datasets
DIANNA comes with simple datasets. Their main goal is to provide intuitive insight into the working of the XAI methods. They can be used as benchmarks for evaluation and comparison of existing and new XAI methods.
Images
| Dataset | Description | Examples | Generation |
|---|---|---|---|
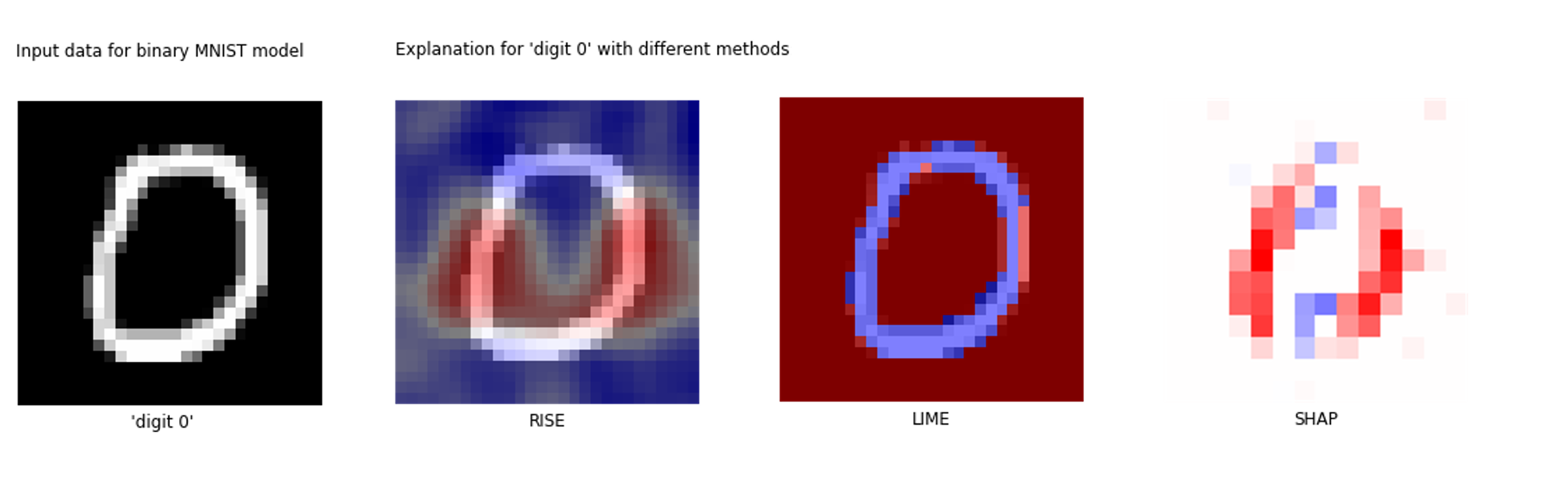
| Binary MNIST |
Greyscale images of the digits "1" and "0" - a 2-class subset from the famousMNIST dataset for handwritten digit classification. |  |
Binary MNIST dataset generation |
| Simple Geometric (circles and triangles) |
Images of circles and triangles for 2-class geometric shape classificaiton. The shapes of varying size and orientation and the background have varying uniform gray levels. |  |
Simple geometric shapes dataset generation |
| Simple Scientific (LeafSnap30) |
Color images of tree leaves - a 30-class post-processed subset from the LeafSnap dataset for automatic identification of North American tree species. |  |
LeafSnap30 dataset generation |
Text
| Dataset | Description | Examples | Generation |
|---|---|---|---|
| Stanford sentiment treebank |
Dataset for predicting the sentiment, positive or negative, of movie reviews. | This movie was actually neither that funny, nor super witty. | Sentiment treebank |
| EU-law statements |
Reproducibility data for a quantitative study on EU legislation. | A Member State wishing to grant exemptions referred to in paragraph 6 shall notify the Council in writing | EU legislation strictness analysis |
Time series
| Dataset | Description | Examples | Generation |
|---|---|---|---|
| Coffee dataset |
Food spectographs time series dataset for a two class problem to distinguish between Robusta and Arabica coffee beans. |  |
data source |
| Weather dataset |
The light version of the weather prediciton dataset, which contains daily observations (89 features) for 11 European locations through the years 2000 to 2010. |  |
data source |
Tabular
| Dataset | Description | Examples | Generation |
|---|---|---|---|
Pengiun dataset  |
Palmer Archipelago (Antarctica) penguin dataset is a great intro dataset for data exploration & visualization similar to the famous Iris dataset. |  |
data source |
| Weather dataset |
The light version of the weather prediciton dataset, which contains daily observations (89 features) for 11 European locations through the years 2000 to 2010. | |
data source |
| Land atmosphere dataset |
It contains land-atmosphere variables and latent heat flux (LEtot) simulated by STEMMUS-SCOPE (soil-plant model), version 1.5.0, over 19 Fluxnet sites and for the year 2014 with hourly intervals. |  |
data source |
Models
We work with ONNX! ONNX is a great unified neural network standard which can be used to boost reproducible science. Using ONNX for your model also gives you a boost in performance! In case your models are still in another popular DNN (deep neural network) format, here are some simple recipes to convert them:
- pytorch and pytorch-lightning - use the built-in
torch.onnx.exportfunction to convert pytorch models to onnx, or call the built-into_onnxfunction on yourLightningModuleto export pytorch-lightning models to onnx. - tensorflow - use the
tf2onnxpackage to convert tensorflow models to onnx. - keras - same as the conversion from tensorflow to onnx, the
tf2onnxpackage also supports keras. - scikit-learn - use the
skl2onnxpackage to scikit-learn models to onnx.
More converters with examples and tutorials can be found on the ONNX tutorial page.
And here are links to notebooks showing how we created our models on the benchmark datasets:
Images
| Models | Generation |
|---|---|
| Binary MNIST model | Binary MNIST model generation |
| Simple Geometric model | Simple geometric shapes model generation |
| Simple Scientific model | LeafSnap30 model generation |
Text
| Models | Generation |
|---|---|
| Movie reviews model | Stanford sentiment treebank model generation |
| Regalatory statement classifier | EU-law regulatory-statement-classification |
Time series
Tabular
We envision the birth of the ONNX Scientific models zoo soon...
Tutorials
DIANNA supports different data modalities and XAI methods (explainers). We have evaluated many explainers using objective criteria (see the How to find your AI explainer blog-post). The table below contains links to the relevant XAI method's papers (for some explanatory videos on the methods, please see tutorials). The DIANNA tutorials cover each supported method and data modality on a least one dataset using the default or tuned hyperparameters. Our plans to expand DIANNA with more data modalities and explainers are given in the ROADMAP.
| Data \ XAI | RISE | LIME | KernelSHAP |
|---|---|---|---|
| Images | ✅ | ✅ | ✅ |
| Text | ✅ | ✅ | |
| Timeseries | ✅ | ✅ | |
| Tabular | planned | ✅ | ✅ |
| Embedding | work in progress | ||
| Graphs* | next steps | ... | ... |
LRP and PatternAttribution also feature in the top 5 of our thoroughly evaluated explainers. Also GradCAM) has been recently found to be semantically continous! Contributing by adding these and more (new) post-hoc explainability methods on ONNX models is very welcome!
Scientific use-cases
Our goal is that the scientific community embrases XAI as a source for novel and unexplored perspectives on scientific problems. Here, we offer tutorials on specific scientific use-cases of uisng XAI:
| Use-case (data) \ XAI | RISE | LIME | KernelSHAP |
|---|---|---|---|
| Biology (Phytomorphology): Tree Leaves classification (images) | ✅ | ||
| Astronomy: Fast Radio Burst detection (timeseries) | ✅ | ||
| Land-atmosphere modeling: Latent heat flux prediction (tabular) | ✅ | ||
| Social sciences: EU-law regulatory statement classification (text) | ✅ | ||
| Climate | planned | ... | ... |
Reference documentation
For detailed information on using specific DIANNA functions, please visit the documentation page hosted at Readthedocs.
Contributing
If you want to contribute to the development of DIANNA, have a look at the contribution guidelines. See our developer documentation for information on developer installation, running tests, generating documentation, versioning and making a release.
How to cite us


If you use this package for your scientific work, please consider citing directly the software as:
Ranguelova, E., Bos, P., Liu, Y., Meijer, C., Oostrum, L., Crocioni, G., Ootes, L., Chandramouli, P., Jansen, A., Smeets, S. (2023). dianna (*[VERSION YOU USED]*). Zenodo. https://zenodo.org/record/5592606
or the JOSS paper as:
Ranguelova et al., (2022). DIANNA: Deep Insight And Neural Network Analysis. Journal of Open Source Software, 7(80), 4493, https://doi.org/10.21105/joss.04493
See also the Zenodo page or the JOSS page for exporting the software citation to BibTteX and other formats.
Credits
This package was created with Cookiecutter and the NLeSC/python-template.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
File details
Details for the file dianna-1.7.0.tar.gz.
File metadata
- Download URL: dianna-1.7.0.tar.gz
- Upload date:
- Size: 12.2 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.9.20
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | be441a91ed93ce8e738d1240ffcc9ff4739b952dc9ceaa05af0ff20e98c7a4da |
|
| MD5 | 5ddfc4c7331a17aee74d7f09ff39af73 |
|
| BLAKE2b-256 | 12aa916e594be95674e0ef3accbeebe25ffddcb04acc6d01936745ce8f20a418 |
File details
Details for the file dianna-1.7.0-py3-none-any.whl.
File metadata
- Download URL: dianna-1.7.0-py3-none-any.whl
- Upload date:
- Size: 12.3 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.9.20
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | c5b19c0bf50d45573192b866df464ba4071aeebe87aa506128c0f1c254e79769 |
|
| MD5 | 8e8345c31cff7789e0a422aa3c5c4a84 |
|
| BLAKE2b-256 | 74d2f682b1915a43b17170bb855f3b5a02d74baedc7f626b6b97268e4dbaaa3e |







