Diffusers




Project description




🤗 Diffusers provides pretrained diffusion models across multiple modalities, such as vision and audio, and serves as a modular toolbox for inference and training of diffusion models.
More precisely, 🤗 Diffusers offers:
- State-of-the-art diffusion pipelines that can be run in inference with just a couple of lines of code (see src/diffusers/pipelines). Check this overview to see all supported pipelines and their corresponding official papers.
- Various noise schedulers that can be used interchangeably for the preferred speed vs. quality trade-off in inference (see src/diffusers/schedulers).
- Multiple types of models, such as UNet, can be used as building blocks in an end-to-end diffusion system (see src/diffusers/models).
- Training examples to show how to train the most popular diffusion model tasks (see examples, e.g. unconditional-image-generation).
Installation
For PyTorch
With pip
pip install --upgrade diffusers[torch]
With conda
conda install -c conda-forge diffusers
For Flax
With pip
pip install --upgrade diffusers[flax]
Apple Silicon (M1/M2) support
Please, refer to the documentation.
Contributing
We ❤️ contributions from the open-source community! If you want to contribute to this library, please check out our Contribution guide. You can look out for issues you'd like to tackle to contribute to the library.
- See Good first issues for general opportunities to contribute
- See New model/pipeline to contribute exciting new diffusion models / diffusion pipelines
- See New scheduler
Also, say 👋 in our public Discord channel 
Quickstart
In order to get started, we recommend taking a look at two notebooks:
- The Getting started with Diffusers
notebook, which showcases an end-to-end example of usage for diffusion models, schedulers and pipelines. Take a look at this notebook to learn how to use the pipeline abstraction, which takes care of everything (model, scheduler, noise handling) for you, and also to understand each independent building block in the library.
- The Training a diffusers model
Stable Diffusion is fully compatible with diffusers!
Stable Diffusion is a text-to-image latent diffusion model created by the researchers and engineers from CompVis, Stability AI, LAION and RunwayML. It's trained on 512x512 images from a subset of the LAION-5B database. This model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 4GB VRAM. See the model card for more information.
You need to accept the model license before downloading or using the Stable Diffusion weights. Please, visit the model card, read the license carefully and tick the checkbox if you agree. You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to this section of the documentation.
Text-to-Image generation with Stable Diffusion
First let's install
pip install --upgrade diffusers transformers scipy
Run this command to log in with your HF Hub token if you haven't before (you can skip this step if you prefer to run the model locally, follow this instead)
huggingface-cli login
We recommend using the model in half-precision (fp16) as it gives almost always the same results as full
precision while being roughly twice as fast and requiring half the amount of GPU RAM.
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, revision="fp16")
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
Running the model locally
If you don't want to login to Hugging Face, you can also simply download the model folder
(after having accepted the license) and pass
the path to the local folder to the StableDiffusionPipeline.
git lfs install
git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
Assuming the folder is stored locally under ./stable-diffusion-v1-5, you can also run stable diffusion
without requiring an authentication token:
pipe = StableDiffusionPipeline.from_pretrained("./stable-diffusion-v1-5")
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
If you are limited by GPU memory, you might want to consider chunking the attention computation in addition
to using fp16.
The following snippet should result in less than 4GB VRAM.
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
revision="fp16",
torch_dtype=torch.float16,
)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
pipe.enable_attention_slicing()
image = pipe(prompt).images[0]
If you wish to use a different scheduler (e.g.: DDIM, LMS, PNDM/PLMS), you can instantiate
it before the pipeline and pass it to from_pretrained.
from diffusers import LMSDiscreteScheduler
pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
If you want to run Stable Diffusion on CPU or you want to have maximum precision on GPU, please run the model in the default full-precision setting:
# make sure you're logged in with `huggingface-cli login`
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
# disable the following line if you run on CPU
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
JAX/Flax
Diffusers offers a JAX / Flax implementation of Stable Diffusion for very fast inference. JAX shines specially on TPU hardware because each TPU server has 8 accelerators working in parallel, but it runs great on GPUs too.
Running the pipeline with the default PNDMScheduler:
import jax
import numpy as np
from flax.jax_utils import replicate
from flax.training.common_utils import shard
from diffusers import FlaxStableDiffusionPipeline
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", revision="flax", dtype=jax.numpy.bfloat16
)
prompt = "a photo of an astronaut riding a horse on mars"
prng_seed = jax.random.PRNGKey(0)
num_inference_steps = 50
num_samples = jax.device_count()
prompt = num_samples * [prompt]
prompt_ids = pipeline.prepare_inputs(prompt)
# shard inputs and rng
params = replicate(params)
prng_seed = jax.random.split(prng_seed, jax.device_count())
prompt_ids = shard(prompt_ids)
images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
Note:
If you are limited by TPU memory, please make sure to load the FlaxStableDiffusionPipeline in bfloat16 precision instead of the default float32 precision as done above. You can do so by telling diffusers to load the weights from "bf16" branch.
import jax
import numpy as np
from flax.jax_utils import replicate
from flax.training.common_utils import shard
from diffusers import FlaxStableDiffusionPipeline
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", revision="bf16", dtype=jax.numpy.bfloat16
)
prompt = "a photo of an astronaut riding a horse on mars"
prng_seed = jax.random.PRNGKey(0)
num_inference_steps = 50
num_samples = jax.device_count()
prompt = num_samples * [prompt]
prompt_ids = pipeline.prepare_inputs(prompt)
# shard inputs and rng
params = replicate(params)
prng_seed = jax.random.split(prng_seed, jax.device_count())
prompt_ids = shard(prompt_ids)
images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
Image-to-Image text-guided generation with Stable Diffusion
The StableDiffusionImg2ImgPipeline lets you pass a text prompt and an initial image to condition the generation of new images.
import requests
import torch
from PIL import Image
from io import BytesIO
from diffusers import StableDiffusionImg2ImgPipeline
# load the pipeline
device = "cuda"
model_id_or_path = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
model_id_or_path,
revision="fp16",
torch_dtype=torch.float16,
)
# or download via git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
# and pass `model_id_or_path="./stable-diffusion-v1-5"`.
pipe = pipe.to(device)
# let's download an initial image
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")
init_image = init_image.resize((768, 512))
prompt = "A fantasy landscape, trending on artstation"
images = pipe(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
images[0].save("fantasy_landscape.png")
You can also run this example on colab
In-painting using Stable Diffusion
The StableDiffusionInpaintPipeline lets you edit specific parts of an image by providing a mask and a text prompt. It uses a model optimized for this particular task, whose license you need to accept before use.
Please, visit the model card, read the license carefully and tick the checkbox if you agree. Note that this is an additional license, you need to accept it even if you accepted the text-to-image Stable Diffusion license in the past. You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to this section of the documentation.
import PIL
import requests
import torch
from io import BytesIO
from diffusers import StableDiffusionInpaintPipeline
def download_image(url):
response = requests.get(url)
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
init_image = download_image(img_url).resize((512, 512))
mask_image = download_image(mask_url).resize((512, 512))
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"runwayml/stable-diffusion-inpainting",
revision="fp16",
torch_dtype=torch.float16,
)
pipe = pipe.to("cuda")
prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
Tweak prompts reusing seeds and latents
You can generate your own latents to reproduce results, or tweak your prompt on a specific result you liked. This notebook shows how to do it step by step. You can also run it in Google Colab
For more details, check out the Stable Diffusion notebook
Fine-Tuning Stable Diffusion
Fine-tuning techniques make it possible to adapt Stable Diffusion to your own dataset, or add new subjects to it. These are some of the techniques supported in diffusers:
Textual Inversion is a technique for capturing novel concepts from a small number of example images in a way that can later be used to control text-to-image pipelines. It does so by learning new 'words' in the embedding space of the pipeline's text encoder. These special words can then be used within text prompts to achieve very fine-grained control of the resulting images.
-
Textual Inversion. Capture novel concepts from a small set of sample images, and associate them with new "words" in the embedding space of the text encoder. Please, refer to our training examples or documentation to try for yourself.
-
Dreambooth. Another technique to capture new concepts in Stable Diffusion. This method fine-tunes the UNet (and, optionally, also the text encoder) of the pipeline to achieve impressive results. Please, refer to our training example and training report for additional details and training recommendations.
-
Full Stable Diffusion fine-tuning. If you have a more sizable dataset with a specific look or style, you can fine-tune Stable Diffusion so that it outputs images following those examples. This was the approach taken to create a Pokémon Stable Diffusion model (by Justing Pinkney / Lambda Labs), a Japanese specific version of Stable Diffusion (by Rinna Co. and others. You can start at our text-to-image fine-tuning example and go from there.
Stable Diffusion Community Pipelines
The release of Stable Diffusion as an open source model has fostered a lot of interesting ideas and experimentation. Our Community Examples folder contains many ideas worth exploring, like interpolating to create animated videos, using CLIP Guidance for additional prompt fidelity, term weighting, and much more! Take a look and contribute your own.
Other Examples
There are many ways to try running Diffusers! Here we outline code-focused tools (primarily using DiffusionPipelines and Google Colab) and interactive web-tools.
Running Code
If you want to run the code yourself 💻, you can try out:
# !pip install diffusers["torch"] transformers
from diffusers import DiffusionPipeline
device = "cuda"
model_id = "CompVis/ldm-text2im-large-256"
# load model and scheduler
ldm = DiffusionPipeline.from_pretrained(model_id)
ldm = ldm.to(device)
# run pipeline in inference (sample random noise and denoise)
prompt = "A painting of a squirrel eating a burger"
image = ldm([prompt], num_inference_steps=50, eta=0.3, guidance_scale=6).images[0]
# save image
image.save("squirrel.png")
# !pip install diffusers["torch"]
from diffusers import DDPMPipeline, DDIMPipeline, PNDMPipeline
model_id = "google/ddpm-celebahq-256"
device = "cuda"
# load model and scheduler
ddpm = DDPMPipeline.from_pretrained(model_id) # you can replace DDPMPipeline with DDIMPipeline or PNDMPipeline for faster inference
ddpm.to(device)
# run pipeline in inference (sample random noise and denoise)
image = ddpm().images[0]
# save image
image.save("ddpm_generated_image.png")
Other Image Notebooks:
- image-to-image generation with Stable Diffusion
- tweak images via repeated Stable Diffusion seeds
Diffusers for Other Modalities:
Web Demos
If you just want to play around with some web demos, you can try out the following 🚀 Spaces:
| Model | Hugging Face Spaces |
|---|---|
| Text-to-Image Latent Diffusion |  |
| Faces generator | |
| DDPM with different schedulers | |
| Conditional generation from sketch | |
| Composable diffusion | |
Definitions
Models: Neural network that models $p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)$ (see image below) and is trained end-to-end to denoise a noisy input to an image. Examples: UNet, Conditioned UNet, 3D UNet, Transformer UNet

Figure from DDPM paper (https://arxiv.org/abs/2006.11239).
Schedulers: Algorithm class for both inference and training. The class provides functionality to compute previous image according to alpha, beta schedule as well as predict noise for training. Also known as Samplers. Examples: DDPM, DDIM, PNDM, DEIS

Sampling and training algorithms. Figure from DDPM paper (https://arxiv.org/abs/2006.11239).
Diffusion Pipeline: End-to-end pipeline that includes multiple diffusion models, possible text encoders, ... Examples: Glide, Latent-Diffusion, Imagen, DALL-E 2
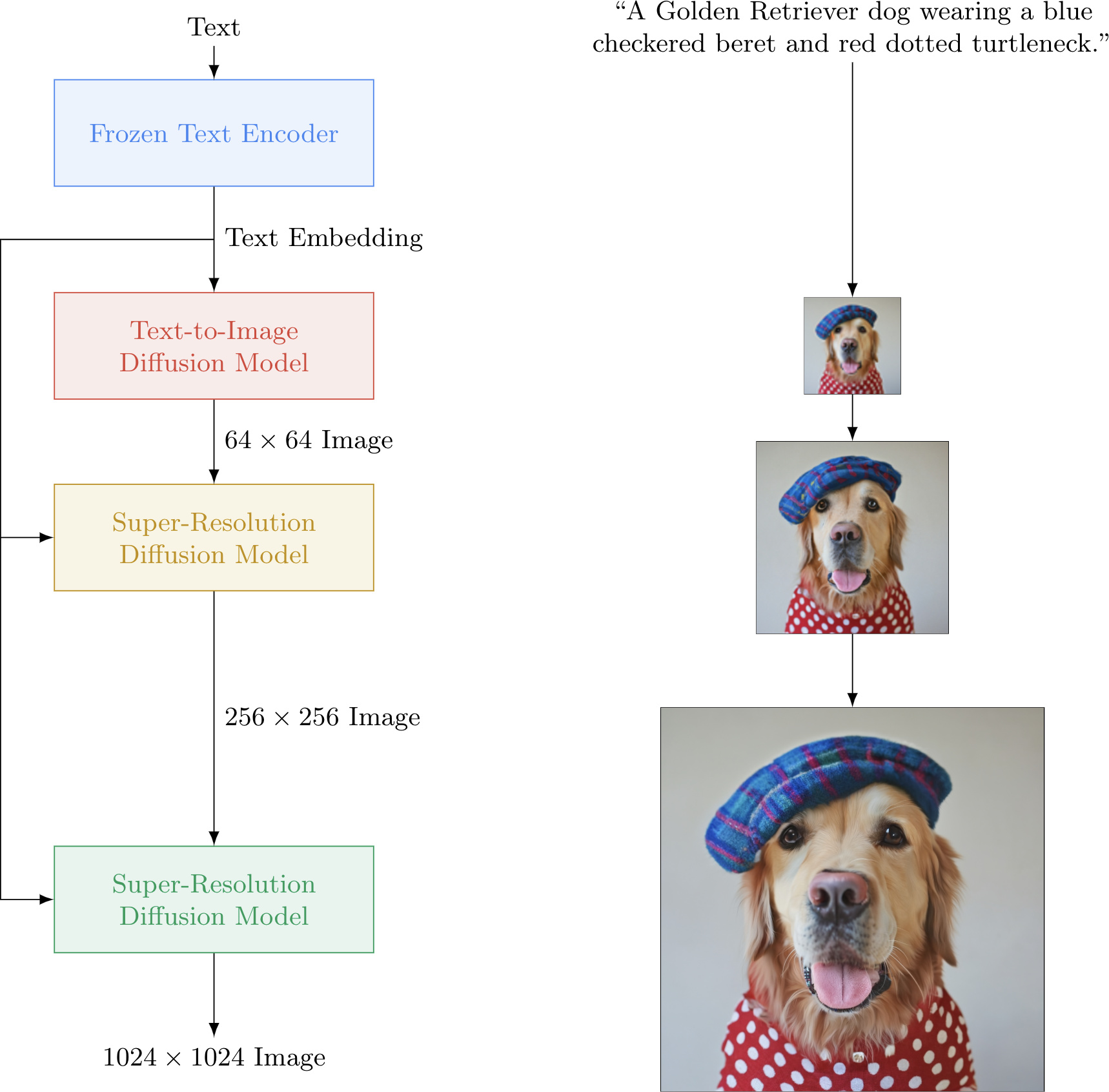
Figure from ImageGen (https://imagen.research.google/).
Philosophy
- Readability and clarity is preferred over highly optimized code. A strong importance is put on providing readable, intuitive and elementary code design. E.g., the provided schedulers are separated from the provided models and provide well-commented code that can be read alongside the original paper.
- Diffusers is modality independent and focuses on providing pretrained models and tools to build systems that generate continuous outputs, e.g. vision and audio.
- Diffusion models and schedulers are provided as concise, elementary building blocks. In contrast, diffusion pipelines are a collection of end-to-end diffusion systems that can be used out-of-the-box, should stay as close as possible to their original implementation and can include components of another library, such as text-encoders. Examples for diffusion pipelines are Glide and Latent Diffusion.
In the works
For the first release, 🤗 Diffusers focuses on text-to-image diffusion techniques. However, diffusers can be used for much more than that! Over the upcoming releases, we'll be focusing on:
- Diffusers for audio
- Diffusers for reinforcement learning (initial work happening in https://github.com/huggingface/diffusers/pull/105).
- Diffusers for video generation
- Diffusers for molecule generation (initial work happening in https://github.com/huggingface/diffusers/pull/54)
A few pipeline components are already being worked on, namely:
- BDDMPipeline for spectrogram-to-sound vocoding
- GLIDEPipeline to support OpenAI's GLIDE model
- Grad-TTS for text to audio generation / conditional audio generation
We want diffusers to be a toolbox useful for diffusers models in general; if you find yourself limited in any way by the current API, or would like to see additional models, schedulers, or techniques, please open a GitHub issue mentioning what you would like to see.
Credits
This library concretizes previous work by many different authors and would not have been possible without their great research and implementations. We'd like to thank, in particular, the following implementations which have helped us in our development and without which the API could not have been as polished today:
- @CompVis' latent diffusion models library, available here
- @hojonathanho original DDPM implementation, available here as well as the extremely useful translation into PyTorch by @pesser, available here
- @ermongroup's DDIM implementation, available here.
- @yang-song's Score-VE and Score-VP implementations, available here
We also want to thank @heejkoo for the very helpful overview of papers, code and resources on diffusion models, available here as well as @crowsonkb and @rromb for useful discussions and insights.
Citation
@misc{von-platen-etal-2022-diffusers,
author = {Patrick von Platen and Suraj Patil and Anton Lozhkov and Pedro Cuenca and Nathan Lambert and Kashif Rasul and Mishig Davaadorj and Thomas Wolf},
title = {Diffusers: State-of-the-art diffusion models},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/huggingface/diffusers}}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
File details
Details for the file diffusers-0.10.0.tar.gz.
File metadata
- Download URL: diffusers-0.10.0.tar.gz
- Upload date:
- Size: 302.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.10.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 7045ae3077b3c898bd027149579c00105e8e4a4b4cbd76b4a89b8d666c907f6c |
|
| MD5 | 6bce692b0649227f50adc182cfa726de |
|
| BLAKE2b-256 | a702d905467fd55988129541ccb78b242f159d010fd01273ceef327b7e0dfc89 |
File details
Details for the file diffusers-0.10.0-py3-none-any.whl.
File metadata
- Download URL: diffusers-0.10.0-py3-none-any.whl
- Upload date:
- Size: 502.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.10.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 47cb3b7441363f82f754e97063e9038c8a5ceae81fc799107733ffc3bd50ec97 |
|
| MD5 | 6dbdef170a4944c2833a838682d0cac2 |
|
| BLAKE2b-256 | 61b85d5fbee2660eb24ccb5802e0b3f4d954656e49bbdb4eca3272de5d2d90f3 |







