A memory profiler for data batch processing applications.

Project description
The Fil memory profiler for Python
Your code reads some data, processes it, and uses too much memory. In order to reduce memory usage, you need to figure out:
- Where peak memory usage is, also known as the high-water mark.
- What code was responsible for allocating the memory that was present at that peak moment.
That's exactly what Fil will help you find. Fil an open source memory profiler designed for data processing applications written in Python, and includes native support for Jupyter.
At the moment it only runs on Linux and macOS, and while it supports threading, it does not yet support multiprocessing or multiple processes in general.
"Within minutes of using your tool, I was able to identify a major memory bottleneck that I never would have thought existed. The ability to track memory allocated via the Python interface and also C allocation is awesome, especially for my NumPy / Pandas programs."
—Derrick Kondo
For more information, including an example of the output, see https://pythonspeed.com/products/filmemoryprofiler/
- Fil vs. other Python memory tools
- Installation
- Using Fil
- Reducing memory usage in your code
- How Fil works
Fil vs. other Python memory tools
There are two distinct patterns of Python usage, each with its own source of memory problems.
In a long-running server, memory usage can grow indefinitely due to memory leaks. That is, some memory is not being freed.
- If the issue is in Python code, tools like
tracemallocand Pympler can tell you which objects are leaking and what is preventing them from being leaked. - If you're leaking memory in C code, you can use tools like Valgrind.
Fil, however, is not aimed at memory leaks, but at the other use case: data processing applications. These applications load in data, process it somehow, and then finish running.
The problem with these applications is that they can, on purpose or by mistake, allocate huge amounts of memory. It might get freed soon after, but if you allocate 16GB RAM and only have 8GB in your computer, the lack of leaks doesn't help you.
Fil will therefore tell you, in an easy to understand way:
- Where peak memory usage is, also known as the high-water mark.
- What code was responsible for allocating the memory that was present at that peak moment.
- This includes C/Fortran/C++/whatever extensions that don't use Python's memory allocation API (
tracemalloconly does Python memory APIs).
This allows you to optimize that code in a variety of ways.
Installation
Assuming you're on macOS or Linux, and are using Python 3.6 or later, you can use either Conda or pip (or any tool that is pip-compatible and can install manylinux2010 wheels).
Conda
To install on Conda:
$ conda install -c conda-forge filprofiler
Pip
To install the latest version of Fil you'll need Pip 19 or newer. You can check like this:
$ pip --version
pip 19.3.0
If you're using something older than v19, you can upgrade by doing:
$ pip install --upgrade pip
If that doesn't work, try running your code in a virtualenv:
$ python3 -m venv venv/
$ . venv/bin/activate
(venv) $ pip install --upgrade pip
Assuming you have a new enough version of pip:
$ pip install filprofiler
Using Fil
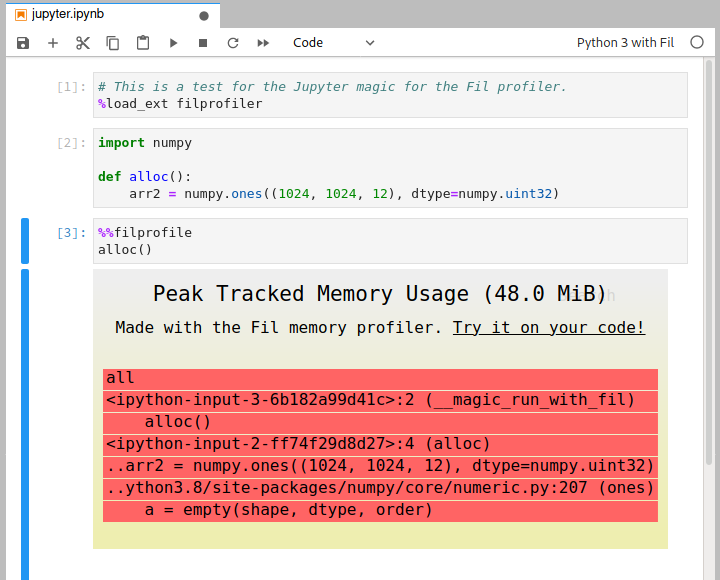
Profiling in Jupyter
To measure peak memory usage of some code in Jupyter you need to do three things:
- Use an alternative kernel, "Python 3 with Fil". You can choose this kernel when you create a new notebook, or you can switch an existing notebook in the Kernel menu; there should be a "Change Kernel" option in there in both Jupyter Notebook and JupyterLab.
- Load the extension by doing
%load_ext filprofiler. - Add the
%%filprofilemagic to the top of the cell with the code you wish to profile.
Profiling complete Python programs
Instead of doing:
$ python yourscript.py --input-file=yourfile
Just do:
$ fil-profile run yourscript.py --input-file=yourfile
And it will generate a report and automatically try to open it in for you in a browser.
Reports will be stored in the fil-result/ directory in your current working directory.
As of version 0.11, you can also run it like this:
$ python -m filprofiler run yourscript.py --input-file=yourfile
API for profiling specific Python functions
You can also measure memory usage in part of your program; this requires version 0.15 or later. This requires two steps.
1. Add profiling in your code
Let's you have some code that does the following:
def main():
config = load_config()
result = run_processing(config)
generate_report(result)
You only want to get memory profiling for the run_processing() call.
You can do so in the code like so:
from filprofiler.api import profile
def main():
config = load_config()
result = profile(lambda: run_processing(config), "/tmp/fil-result")
generate_report(result)
You could also make it conditional, e.g. based on an environment variable:
import os
from filprofiler.api import profile
def main():
config = load_config()
if os.environ.get("FIL_PROFILE"):
result = profile(lambda: run_processing(config), "/tmp/fil-result")
else:
result = run_processing(config)
generate_report(result)
2. Run your script with Fil
You still need to run your program in a special way. If previously you did:
$ python yourscript.py --config=myconfig
Now you would do:
$ filprofiler python yourscript.py --config=myconfig
Notice that you're doing filprofiler python, rather than filprofiler run as you would if you were profiling the full script.
Only functions explicitly called with the filprofiler.api.profile() will have memory profiling enabled; the rest of the code will run at (close) to normal speed and configuration.
Each call to profile() will generate a separate report.
The memory profiling report will be written to the directory specified as the output destination when calling profile(); in or example above that was "/tmp/fil-result".
Unlike full-program profiling:
- The directory you give will be used directly, there won't be timestamped sub-directories.
If there are multiple calls to
profile(), it is your responsibility to ensure each call writes to a unique directory. - The report(s) will not be opened in a browser automatically, on the presumption you're running this in an automated fashion.
Debugging out-of-memory crashes
New in v0.14 and later: Just run your program under Fil, and it will generate a SVG at the point in time when memory runs out, and then exit with exit code 53:
$ fil-profile run oom.py
...
=fil-profile= Wrote memory usage flamegraph to fil-result/2020-06-15T12:37:13.033/out-of-memory.svg
Fil uses three heuristics to determine if the process is close to running out of memory:
- A failed allocation, indicating insufficient memory is available.
- The operating system or memory-limited cgroup (e.g. a Docker container) only has 100MB of RAM available.
- The process swap is larger than available memory, indicating heavy swapping by the process.
In general you want to avoid swapping, and e.g. explicitly use
mmap()if you expect to be using disk as a backfill for memory.
Reducing memory usage in your code
You've found where memory usage is coming from—now what?
If you're using data processing or scientific computing libraries, I have written a relevant guide to reducing memory usage.
How Fil works
Fil uses the LD_PRELOAD/DYLD_INSERT_LIBRARIES mechanism to preload a shared library at process startup.
This shared library captures all memory allocations and deallocations and keeps track of them.
At the same time, the Python tracing infrastructure (used e.g. by cProfile and coverage.py) to figure out which Python callstack/backtrace is responsible for each allocation.
For performance reasons, only the largest allocations are reported, with a minimum of 99% of allocated memory reported. The remaining <1% is highly unlikely to be relevant when trying to reduce usage; it's effectively noise.
Fil and threading, with notes on NumPy and Zarr {#threading}
In general, Fil will track allocations in threads correctly.
First, if you start a thread via Python, running Python code, that thread will get its own callstack for tracking who is responsible for a memory allocation.
Second, if you start a C thread, the calling Python code is considered responsible for any memory allocations in that thread. This works fine... except for thread pools. If you start a pool of threads that are not Python threads, the Python code that created those threads will be responsible for all allocations created during the thread pool's lifetime.
Therefore, in order to ensure correct memory tracking, Fil disables thread pools in BLAS (used by NumPy), BLOSC (used e.g. by Zarr), OpenMP, and numexpr.
They are all set to use 1 thread, so calls should run in the calling Python thread and everything should be tracked correctly.
This has some costs:
- This can reduce performance in some cases, since you're doing computation with one CPU instead of many.
- Insofar as these libraries allocate memory proportional to number of threads, the measured memory usage might be wrong.
Fil does this for the whole program when using fil-profile run.
When using the Jupyter kernel, anything run with the %%filprofile magic will have thread pools disabled, but other code should run normally.
What Fil tracks
Fil will track memory allocated by:
- Normal Python code.
- C code using
malloc()/calloc()/realloc()/posix_memalign(). - C++ code using
new(including viaaligned_alloc()). - Anonymous
mmap()s. - Fortran 90 explicitly allocated memory (tested with gcc's
gfortran).
Still not supported, but planned:
mremap()(resizing ofmmap()).- File-backed
mmap(). The semantics are somewhat different than normal allocations or anonymousmmap(), since the OS can swap it in or out from disk transparently, so supporting this will involve a different kind of resource usage and reporting. - Other forms of shared memory, need to investigate if any of them allow sufficient allocation.
- Anonymous
mmap()s created via/dev/zero(not common, since it's not cross-platform, e.g. macOS doesn't support this). memfd_create(), a Linux-only mechanism for creating in-memory files.- Possibly
memalign,valloc(),pvalloc(),reallocarray(). These are all rarely used, as far as I can tell.
License
Copyright 2020 Hyphenated Enterprises LLC
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distributions
Hashes for filprofiler-0.15.0-cp39-cp39-manylinux2010_x86_64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | cf15fb951a812d0b8c91df645e4904424b307442e9238f04d87d5adb17757006 |
|
| MD5 | 21f93e71895b302066708d59947e1153 |
|
| BLAKE2b-256 | 4c1c01f448f48f50d5c643f5ac69693868bd2ade0d58e47f9409ebf486532320 |
Hashes for filprofiler-0.15.0-cp38-cp38-manylinux2010_x86_64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 501551707a8e505088a8c6858a945665d2c187393a06cecadc98eb312a2b7acc |
|
| MD5 | da8af87ba9285ed32ea4e59d740282fd |
|
| BLAKE2b-256 | 61bf4fd94a5b32c5255dbe7edbcd01e26de03e7b173434833a111830cc0e353c |
Hashes for filprofiler-0.15.0-cp37-cp37m-manylinux2010_x86_64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 56e4959814b797ba926418d734c7616630a5657899a7607101b96e80715e56d4 |
|
| MD5 | 53302597c9d82f08ef1246dcef15f423 |
|
| BLAKE2b-256 | c2189395855731915407406de4c12f55f69c449f16097bfb7349bfe1851b924b |
Hashes for filprofiler-0.15.0-cp36-cp36m-manylinux2010_x86_64.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | b3823a0904519a67cb0bba7d35ac0908222c2d9accfe125348c298251ed257e3 |
|
| MD5 | 3ed120460dbe447cfdb0f5084cd3c8fb |
|
| BLAKE2b-256 | 2a82f5be62cb7e9efe1c676c09196057e7402beebded73d38c475a2b904b0021 |







