Build flask project with Firebase

Project description
flask-boiler
Flask-boiler helps you build fast-prototype of your backend.
Architecture Diagram
You may structure your project in this way:
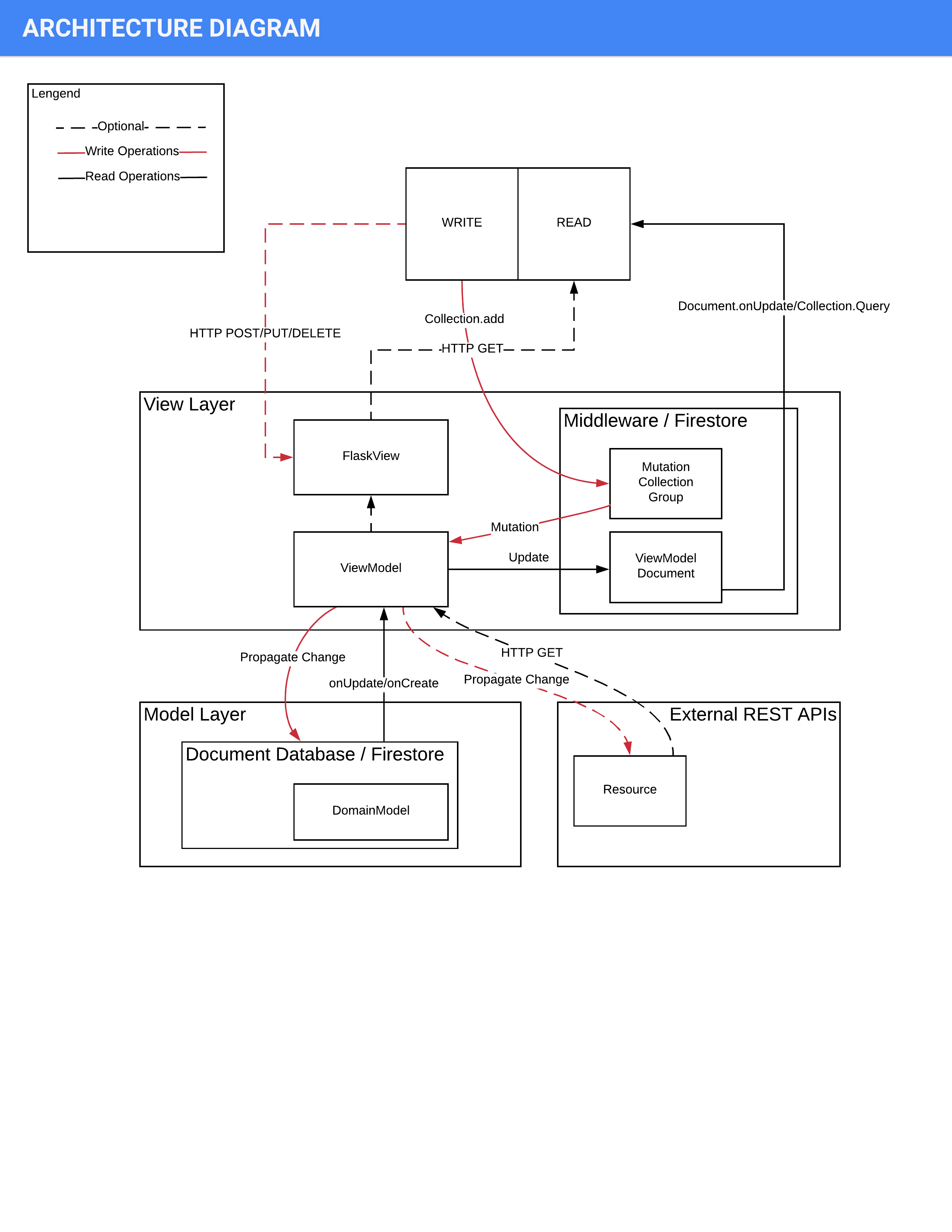
Features
Context Management
In __init__ of your project source root:
import os
from flask_boiler import context
from flask_boiler import config
Config = config.Config
testing_config = Config(app_name="your_app_name",
debug=True,
testing=True,
certificate_path=os.path.curdir + "/../your_project/config_jsons/your_certificate.json")
CTX = context.Context
CTX.read(testing_config)
Note that initializing Config with certificate_path is unstable and
may be changed later.
In your project code,
from flask_boiler import context
CTX = context.Context
# Retrieves firestore database instance
CTX.db
# Retrieves firebase app instance
CTX.firebase_app
ORM
from flask_boiler.factory import ClsFactory
from flask_boiler import schema, fields
# Creates a schema for serializing and deserializing to firestore database
class TestObjectSchema(schema.Schema):
# Describes how obj.int_a is read from and stored to a document in firestore
int_a = fields.Raw(
load_from="intA", # reads obj.int_a from firestore document field "intA"
dump_to="intA" # stores the value of obj.int_a to firestore document field "intA"
)
int_b = fields.Raw(load_from="intB", dump_to="intB")
# Declares the object
TestObject = ClsFactory.create(
name="TestObject",
schema=TestObjectSchema,
# Either MyDomainModelBase (specify cls._collection_id)
# or SubclassOfViewModel
# TODO: ADD MORE DOCS
base=PrimaryObject
)
# Creates an object with default values with reference: "TestObject/testObjId1"
# (but not saved to database)
obj = TestObject.create(doc_id="testObjId1")
# Assigns value to the newly created object
obj.int_a = 1
obj.int_b = 2
# Saves to firestore "TestObject/testObjId1"
obj.save()
# Gets the object from firestore "TestObject/testObjId1"
retrieved_obj = TestObject.get(doc_id="testObjId1")
# Access values of the object retrieved
assert retrieved_obj.int_a == 1
assert retrieved_obj.int_b == 2
# Deletes the object from firestore "TestObject/testObjId1"
retrieved_obj.delete()
Architecture Discussion
Disambiguation
There are 2+ ways to run the view layer.
-
Document-As-View: Persist all view models to firestore, and client reads/writes to firestore.
- Document is refreshed every time the bounding domain models change
- Firestore serves Document at near 0 latency (cached) if the client attaches a listener to the view model
- Performance depends on how often the domain model is changed
-
Flask-As-View: only the binding structure is persisted, and client reads/writes to flask REST API resources.
- Bounding domain models are read every time the client requests the resource
- May experience latency, but overall lower in server cost since the ViewModel is not persisted
- Performance depends on how often the view model is read
-
A combination of 1 and 2: build read-intensive microservices with Document-As-View and change-intensive microservices with Flask-As-View.
Flask-boiler is mostly for building a fast prototype of your backend. As you keep developing your product, we recommend that you switch to a relational database for your domain model layer if your data has many references, and WebSocket/REST API for view layer. This does not mean that flask-boiler is not runtime efficient, but that simplicity is always a compromise and firestore can be expensive.
Performance
Document-As-View has better performance if data is read more than it's changed, and the view models served are limited or specific to a user.
Flask-As-View has better performance when the domain model is changed often, and the client rarely reads all data available to a specific user.
Flask-boiler is not a well-tested concept, but criticisms are welcomed. At least, we can strive to build a backend framework that is simple and friendly to beginners who want to prototype their backend easily so that they can focus on transforming ideas.
Advantages
Decoupled Domain Model and View Model
Using Firebase Firestore sometimes require duplicated fields across several documents in order to both query the data and display them properly in front end. Flask-boiler solves this problem by decoupling domain model and view model. View model are generated and refreshed automatically as domain model changes. This means that you will only have to write business logics on the domain model without worrying about how the data will be displayed. This also means that the View Models can be displayed directly in front end, while supporting real-time features of Firebase Firestore.
One-step Configuration
Rather than configuring the network and different certificate settings for your database and other cloud services. All you have to do is to enable related services on Google Cloud Console, and add your certificate. Flask-boiler configures all the services you need, and expose them as a singleton Context object across the project.
Redundancy
Since all View Models are persisted in Firebase Firestore. Even if your App Instance is offline, the users can still access a view of the data from Firebase Firestore. Every View is also a Flask View, so you can also access the data with auto-generated REST API, in case Firebase Firestore is not viable.
Added Safety
By separating business data from documents that are accessible to the front end, you have more control over which data is displayed depending on the user's role.
One-step Documentation
All ViewModels have automatically generated documentations (provided by Flasgger). This helps AGILE teams keep their documentations and actual code in sync.
Fully-extendable
When you need better performance or relational database
support, you can always refactor a specific layer by
adding modules such as flask-sqlalchemy.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file flask_boiler-0.0.1a3.tar.gz.
File metadata
- Download URL: flask_boiler-0.0.1a3.tar.gz
- Upload date:
- Size: 22.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.20.0 setuptools/40.5.0 requests-toolbelt/0.9.1 tqdm/4.35.0 CPython/2.7.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | c434bc3d165924556428fd530dfa0ead3af825b91312f13dd1255cb06d38fe83 |
|
| MD5 | 0a92f2d5d2dd2d7d7ec799e174451d83 |
|
| BLAKE2b-256 | fc41eb93dbfa2ce76c7137a17147b1b2e8ccc08ee35fa4f080ccfb4ac87ec843 |







