The kwcoco Module


Project description






The main webpage for this project is: https://gitlab.kitware.com/computer-vision/kwcoco
The Kitware COCO module defines a variant of the Microsoft COCO format, originally developed for the “collected images in context” object detection challenge. We are backwards compatible with the original module, but we also have improved implementations in several places, including segmentations and keypoints.
The main data structure in this model is largely based on the implementation in https://github.com/cocodataset/cocoapi It uses the same efficient core indexing data structures, but in our implementation the indexing can be optionally turned off, functions are silent by default (with the exception of long running processes, which optionally show progress by default). We support helper functions that add and remove images, categories, and annotations.
We have reimplemented the object detection scoring code in the kwcoco.metrics submodule.
The original pycocoutils API is exposed via the kwcoco.compat_dataset.COCO class for drop-in replacement with existing tools that use pycocoutils.
There is some support for kw18 files in the kwcoco.kw18 module.
The kwcoco CLI
After installing kwcoco, you will also have the kwcoco command line tool. This uses a scriptconfig / argparse CLI interface. Running kwcoco --help should provide a good starting point.
usage: kwcoco [-h] {stats,union,split,show,toydata,eval,modify_categories} ...
The Kitware COCO CLI
positional arguments:
{stats,union,split,show,toydata,eval,modify_categories}
specify a command to run
stats Compute summary statistics about a COCO dataset
union Combine multiple COCO datasets into a single merged dataset.
split Split a single COCO dataset into two sub-datasets.
show Visualize a COCO image using matplotlib, optionally writing it to disk
toydata Create COCO toydata
eval Evaluate and score predicted versus truth detections / classifications in a COCO dataset
modify_categories Rename or remove categories
optional arguments:
-h, --help show this help message and exitThis should help you inspect (via stats and show), combine (via union), and make training splits (via split) using the command line. Also ships with toydata, which generates a COCO file you can use for testing.
Toy Data
Don’t have a dataset with you, but you still want to test out your algorithms? Try the kwcoco shapes demo dataset, and generate an arbitrarilly large dataset.
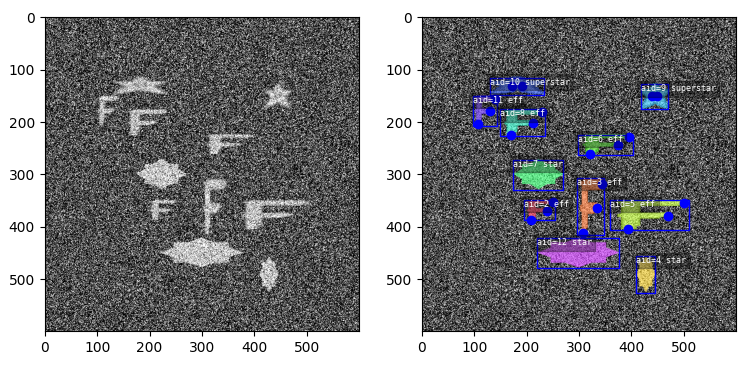
The toydata submodule renders simple objects on a noisy background — optionally with auxillary channels — and provides bounding boxes, segmentations, and keypoint annotations. The following example illustrates a generated toy image with and without overlaid annotations.
The CocoDataset object
The kwcoco.CocoDataset class is capable of dynamic addition and removal of categories, images, and annotations. Has better support for keypoints and segmentation formats than the original COCO format. Despite being written in Python, this data structure is reasonably efficient.
>>> import kwcoco
>>> import json
>>> # Create demo data
>>> demo = CocoDataset.demo()
>>> # could also use demo.dump / demo.dumps, but this is more explicit
>>> text = json.dumps(demo.dataset)
>>> with open('demo.json', 'w') as file:
>>> file.write(text)
>>> # Read from disk
>>> self = CocoDataset('demo.json')
>>> # Add data
>>> cid = self.add_category('Cat')
>>> gid = self.add_image('new-img.jpg')
>>> aid = self.add_annotation(image_id=gid, category_id=cid, bbox=[0, 0, 100, 100])
>>> # Remove data
>>> self.remove_annotations([aid])
>>> self.remove_images([gid])
>>> self.remove_categories([cid])
>>> # Look at data
>>> print(ub.repr2(self.basic_stats(), nl=1))
>>> print(ub.repr2(self.extended_stats(), nl=2))
>>> print(ub.repr2(self.boxsize_stats(), nl=3))
>>> print(ub.repr2(self.category_annotation_frequency()))
>>> # Inspect data
>>> import kwplot
>>> kwplot.autompl()
>>> self.show_image(gid=1)
>>> # Access single-item data via imgs, cats, anns
>>> cid = 1
>>> self.cats[cid]
{'id': 1, 'name': 'astronaut', 'supercategory': 'human'}
>>> gid = 1
>>> self.imgs[gid]
{'id': 1, 'file_name': 'astro.png', 'url': 'https://i.imgur.com/KXhKM72.png'}
>>> aid = 3
>>> self.anns[aid]
{'id': 3, 'image_id': 1, 'category_id': 3, 'line': [326, 369, 500, 500]}
# Access multi-item data via the annots and images helper objects
>>> aids = self.index.gid_to_aids[2]
>>> annots = self.annots(aids)
>>> print('annots = {}'.format(ub.repr2(annots, nl=1, sv=1)))
annots = <Annots(num=2)>
>>> annots.lookup('category_id')
[6, 4]
>>> annots.lookup('bbox')
[[37, 6, 230, 240], [124, 96, 45, 18]]
>>> # built in conversions to efficient kwimage array DataStructures
>>> print(ub.repr2(annots.detections.data))
{
'boxes': <Boxes(xywh,
array([[ 37., 6., 230., 240.],
[124., 96., 45., 18.]], dtype=float32))>,
'class_idxs': np.array([5, 3], dtype=np.int64),
'keypoints': <PointsList(n=2) at 0x7f07eda33220>,
'segmentations': <PolygonList(n=2) at 0x7f086365aa60>,
}
>>> gids = list(self.imgs.keys())
>>> images = self.images(gids)
>>> print('images = {}'.format(ub.repr2(images, nl=1, sv=1)))
images = <Images(num=3)>
>>> images.lookup('file_name')
['astro.png', 'carl.png', 'stars.png']
>>> print('images.annots = {}'.format(images.annots))
images.annots = <AnnotGroups(n=3, m=3.7, s=3.9)>
>>> print('images.annots.cids = {!r}'.format(images.annots.cids))
images.annots.cids = [[1, 2, 3, 4, 5, 5, 5, 5, 5], [6, 4], []]The JSON Spec
A COCO file is a json file that follows a particular spec. It is used for storing computer vision datasets: namely images, categories, and annotations. Images have an id and a file name, which holds a relative or absolute path to the image data. Images can also have auxillary files (e.g. for depth masks, infared, or motion). A category has an id, a name, and an optional supercategory. Annotations always have an id, an image-id, and a bounding box. Usually they also contain a category-id. Sometimes they contain keypoints, segmentations. The dataset can also store videos, in which case images should have video_id field, and annotations should have a track_id field.
An implementation and extension of the original MS-COCO API [1].
Dataset Spec:
category = {
'id': int,
'name': str,
'supercategory': Optional[str],
'keypoints': Optional(List[str]),
'skeleton': Optional(List[Tuple[Int, Int]]),
}
image = {
'id': int,
'file_name': str
}
dataset = {
# these are object level categories
'categories': [category],
'images': [image]
...
],
'annotations': [
{
'id': Int,
'image_id': Int,
'category_id': Int,
'track_id': Optional[Int],
'bbox': [tl_x, tl_y, w, h], # optional (xywh format)
"score" : float, # optional
"prob" : List[float], # optional
"weight" : float, # optional
"caption": str, # an optional text caption for this annotation
"iscrowd" : <0 or 1>, # denotes if the annotation covers a single object (0) or multiple objects (1)
"keypoints" : [x1,y1,v1,...,xk,yk,vk], # or new dict-based format
'segmentation': <RunLengthEncoding | Polygon>, # formats are defined bellow
},
...
],
'licenses': [],
'info': [],
}
Polygon:
A flattned list of xy coordinates.
[x1, y1, x2, y2, ..., xn, yn]
or a list of flattned list of xy coordinates if the CCs are disjoint
[[x1, y1, x2, y2, ..., xn, yn], [x1, y1, ..., xm, ym],]
Note: the original coco spec does not allow for holes in polygons.
We also allow a non-standard dictionary encoding of polygons
{'exterior': [(x1, y1)...],
'interiors': [[(x1, y1), ...], ...]}
RunLengthEncoding:
The RLE can be in a special bytes encoding or in a binary array
encoding. We reuse the original C functions are in [2]_ in
``kwimage.structs.Mask`` to provide a convinient way to abstract this
rather esoteric bytes encoding.
For pure python implementations see kwimage:
Converting from an image to RLE can be done via kwimage.run_length_encoding
Converting from RLE back to an image can be done via:
kwimage.decode_run_length
For compatibility with the COCO specs ensure the binary flags
for these functions are set to true.
Keypoints:
Annotation keypoints may also be specified in this non-standard (but
ultimately more general) way:
'annotations': [
{
'keypoints': [
{
'xy': <x1, y1>,
'visible': <0 or 1 or 2>,
'keypoint_category_id': <kp_cid>,
'keypoint_category': <kp_name, optional>, # this can be specified instead of an id
}, ...
]
}, ...
],
'keypoint_categories': [{
'name': <str>,
'id': <int>, # an id for this keypoint category
'supercategory': <kp_name> # name of coarser parent keypoint class (for hierarchical keypoints)
'reflection_id': <kp_cid> # specify only if the keypoint id would be swapped with another keypoint type
},...
]
In this scheme the "keypoints" property of each annotation (which used
to be a list of floats) is now specified as a list of dictionaries that
specify each keypoints location, id, and visibility explicitly. This
allows for things like non-unique keypoints, partial keypoint
annotations. This also removes the ordering requirement, which makes it
simpler to keep track of each keypoints class type.
We also have a new top-level dictionary to specify all the possible
keypoint categories.
Auxillary Channels:
For multimodal or multispectral images it is possible to specify
auxillary channels in an image dictionary as follows:
{
'id': int, 'file_name': str
'channels': <spec>, # a spec code that indicates the layout of these channels.
'auxillary': [ # information about auxillary channels
{
'file_name':
'channels': <spec>
}, ... # can have many auxillary channels with unique specs
]
}
Video Sequences:
For video sequences, we add the following video level index:
"videos": [
{ "id": <int>, "name": <video_name:str> },
]
Note that the videos might be given as encoded mp4/avi/etc.. files (in
which case the name should correspond to a path) or as a series of
frames in which case the images should be used to index the extracted
frames and information in them.
Then image dictionaries are augmented as follows:
{
'video_id': str # optional, if this image is a frame in a video sequence, this id is shared by all frames in that sequence.
'timestamp': int # optional, timestamp (ideally in flicks), used to identify the timestamp of the frame. Only applicable video inputs.
'frame_index': int # optional, ordinal frame index which can be used if timestamp is unknown.
}
And annotations are augmented as follows:
{
"track_id": <int | str | uuid> # optional, indicates association between annotations across frames
}Converting your data to COCO
Assuming you have programmatic access to your dataset you can easily convert to a coco file using process similar to the following code:
# ASSUME INPUTS
# my_classes: a list of category names
# my_annots: a list of annotation objects with bounding boxes, images, and categories
# my_images: a list of image files.
my_images = [
'image1.png',
'image2.png',
'image3.png',
]
my_classes = [
'spam', 'eggs', 'ham', 'jam'
]
my_annots = [
{'image': 'image1.png', 'box': {'tl_x': 2, 'tl_y': 3, 'br_x': 5, 'br_y': 7}, 'category': 'spam'},
{'image': 'image1.png', 'box': {'tl_x': 11, 'tl_y': 13, 'br_x': 17, 'br_y': 19}, 'category': 'spam'},
{'image': 'image3.png', 'box': {'tl_x': 23, 'tl_y': 29, 'br_x': 31, 'br_y': 37}, 'category': 'eggs'},
{'image': 'image3.png', 'box': {'tl_x': 41, 'tl_y': 43, 'br_x': 47, 'br_y': 53}, 'category': 'spam'},
{'image': 'image3.png', 'box': {'tl_x': 59, 'tl_y': 61, 'br_x': 67, 'br_y': 71}, 'category': 'jam'},
{'image': 'image3.png', 'box': {'tl_x': 73, 'tl_y': 79, 'br_x': 83, 'br_y': 89}, 'category': 'spam'},
]
# The above is just an example input, it is left as an exercise for the
# reader to translate that to your own dataset.
import kwcoco
import kwimage
# A kwcoco.CocoDataset is simply an object that manages an underlying
# `dataset` json object. It contains methods to dynamically, add, remove,
# and modify these data structures, efficient lookup tables, and many more
# conveniences when working and playing with vision datasets.
my_dset = kwcoco.CocoDataset()
for catname in my_classes:
my_dset.add_category(name=catname)
for image_path in my_images:
my_dset.add_image(file_name=image_path)
for annot in my_annots:
# The index property provides fast lookups into the json data structure
cat = my_dset.index.name_to_cat[annot['category']]
img = my_dset.index.file_name_to_img[annot['image']]
# One quirk of the coco format is you need to be aware that
# boxes are in <top-left-x, top-left-y, width-w, height-h> format.
box = annot['box']
# Use kwimage.Boxes to preform quick, reliable, and readable
# conversions between common bounding box formats.
tlbr = [box['tl_x'], box['tl_y'], box['br_x'], box['br_y']]
xywh = kwimage.Boxes([tlbr], 'tlbr').toformat('xywh').data[0].tolist()
my_dset.add_annotation(bbox=xywh, image_id=img['id'], category_id=cat['id'])
# Dump the underlying json `dataset` object to a file
my_dset.fpath = 'my-converted-dataset.mscoco.json'
my_dset.dump(my_dset.fpath, newlines=True)
# Dump the underlying json `dataset` object to a string
print(my_dset.dumps(newlines=True))Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
File details
Details for the file kwcoco-0.1.10.tar.gz.
File metadata
- Download URL: kwcoco-0.1.10.tar.gz
- Upload date:
- Size: 199.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.3.0 pkginfo/1.7.0 requests/2.25.1 setuptools/52.0.0 requests-toolbelt/0.9.1 tqdm/4.56.0 CPython/3.8.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | fdec6c88ebc275ee48539c4dab82b17cd1abd0a40dfed17803b2f7d7fde893d8 |
|
| MD5 | 37f4f83abda7077205815fd4ca9eee40 |
|
| BLAKE2b-256 | 3bb28632134e334fc0297fe009dbdae57817bb10b08eb5589f9a4f16a4756423 |
File details
Details for the file kwcoco-0.1.10-py3-none-any.whl.
File metadata
- Download URL: kwcoco-0.1.10-py3-none-any.whl
- Upload date:
- Size: 211.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.3.0 pkginfo/1.7.0 requests/2.25.1 setuptools/52.0.0 requests-toolbelt/0.9.1 tqdm/4.56.0 CPython/3.8.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 7a6ee1ac7c99447131895db25a6ffe61b246109346042be2023ca6c4ce3fbf5f |
|
| MD5 | 80825ef692b968f3aea987f5900d89a0 |
|
| BLAKE2b-256 | 074f2491f8d02e2fd4137531375a44a5169193b2d6e651367ede4eb7ace839de |
File details
Details for the file kwcoco-0.1.10-py2.py3-none-any.whl.
File metadata
- Download URL: kwcoco-0.1.10-py2.py3-none-any.whl
- Upload date:
- Size: 211.5 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.3.0 pkginfo/1.7.0 requests/2.25.1 setuptools/52.0.0 requests-toolbelt/0.9.1 tqdm/4.56.0 CPython/3.8.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | e082b12c02d882536271e6784429cbb3f4f784b45309b78ef10d54a52c67e7bf |
|
| MD5 | cb4e53148497a36c77708f028e86dcf3 |
|
| BLAKE2b-256 | 5d3461e1d232290733267bad39af8bd24d667323233dc8baa6585c1615eb970a |







