MLPerf Inference LoadGen python bindings


Project description
Overview {#mainpage}
Introduction
- The LoadGen is a reusable module that efficiently and fairly measures the performance of inference systems.
- It generates traffic for scenarios as formulated by a diverse set of experts in the MLCommons working group.
- The scenarios emulate the workloads seen in mobile devices, autonomous vehicles, robotics, and cloud-based setups.
- Although the LoadGen is not model or dataset aware, its strength is in its reusability with logic that is.
Integration Example and Flow
The following is an diagram of how the LoadGen can be integrated into an inference system, resembling how some of the MLPerf reference models are implemented.

- Benchmark knows the model, dataset, and preprocessing.
- Benchmark hands dataset sample IDs to LoadGen.
- LoadGen starts generating queries of sample IDs.
- Benchmark creates requests to backend.
- Result is post processed and forwarded to LoadGen.
- LoadGen outputs logs for analysis.
Useful Links
- FAQ
- LoadGen Build Instructions
- LoadGen API
- Test Settings - A good description of available scenarios, modes, and knobs.
- MLPerf Inference Code - Includes source for the LoadGen and reference models that use the LoadGen.
- MLPerf Inference Rules - Any mismatch with this is a bug in the LoadGen.
Scope of the LoadGen's Responsibilities
In Scope
- Provide a reusable C++ library with python bindings.
- Implement the traffic patterns of the MLPerf Inference scenarios and modes.
- Record all traffic generated and received for later analysis and verification.
- Summarize the results and whether performance constraints were met.
- Target high-performance systems with efficient multi-thread friendly logging utilities.
- Generate trust via a shared, well-tested, and community-hardened code base.
Out of Scope
The LoadGen is:
- NOT aware of the ML model it is running against.
- NOT aware of the data formats of the model's inputs and outputs.
- NOT aware of how to score the accuracy of a model's outputs.
- NOT aware of MLPerf rules regarding scenario-specific constraints.
Limitting the scope of the LoadGen in this way keeps it reusable across different models and datasets without modification. Using composition and dependency injection, the user can define their own model, datasets, and metrics.
Additionally, not hardcoding MLPerf-specific test constraints, like test duration and performance targets, allows users to use the LoadGen unmodified for custom testing and continuous integration purposes.
Submission Considerations
Upstream all local modifications
- As a rule, no local modifications to the LoadGen's C++ library are allowed for submission.
- Please upstream early and often to keep the playing field level.
Choose your TestSettings carefully!
- Since the LoadGen is oblivious to the model, it can't enforce the MLPerf requirements for submission. e.g.: target percentiles and latencies.
- For verification, the values in TestSettings are logged.
- To help make sure your settings are spec compliant, use TestSettings::FromConfig in conjunction with the relevant config file provided with the reference models.
Responsibilities of a LoadGen User
Implement the Interfaces
- Implement the SystemUnderTest and QuerySampleLibrary interfaces and pass them to the StartTest function.
- Call QuerySampleComplete for every sample received by SystemUnderTest::IssueQuery.
Assess Accuracy
- Process the mlperf_log_accuracy.json output by the LoadGen to determine the accuracy of your system.
- For the official models, Python scripts will be provided by the MLPerf model owners for you to do this automatically.
For templates of how to do the above in detail, refer to code for the demos, tests, and reference models.
LoadGen over the Network
For reference, on a high level a submission looks like this:
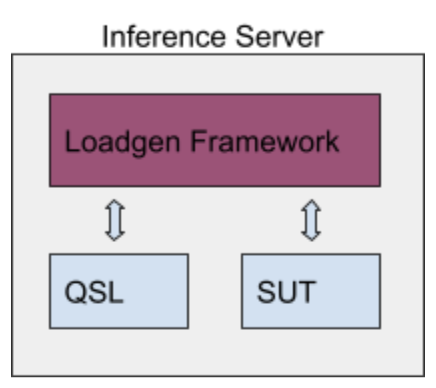
The LoadGen implementation is common to all submissions, while the QSL (“Query Sample Library”) and SUT (“System Under Test”) are implemented by submitters. QSL is responsible for loading the data and includes untimed preprocessing.
A submission over the network introduces a new component “QDL” (query dispatch library) that is added to the system as presented in the following diagram:
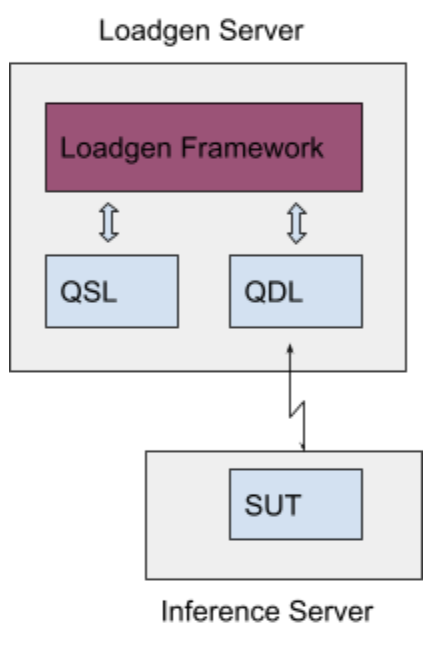
QDL is a proxy for a load-balancer, that dispatches queries to SUT over a physical network, receives the responses and passes them back to LoadGen. It is implemented by the submitter. The interface of the QDL is the same as the API to SUT.
In scenarios using QDL, data may be compressed in QSL at the choice of the submitter in order to reduce network transmission time. Decompression is part of the timed processing in SUT. A set of approved standard compression schemes will be specified for each benchmark; additional compression schemes must be approved in advance by the Working Group.
All communication between LoadGen/QSL and SUT is via QDL, and all communication between QDL and SUT must pass over a physical network.
QDL implements the protocol to transmit queries over the network and receive responses. It also implements decompression of any response returned by the SUT, where compression of responses is allowed. Performing any part of the timed preprocessing or inference in QDL is specifically disallowed. Currently no batching is allowed in QDL, although this may be revisited in future.
The MLperf over the Network will run in Server mode and Offline mode. All LoadGen modes are expected to work as is with insignificant changes. These include running the test in performance mode, accuracy mode, find peak performance mode and compliance mode. The same applies for power measurements.
QDL details
The Query Dispatch Library is implemented by the submitter and interfaces with LoadGen using the same SUT API. All MLPerf Inference SUTs implement the mlperf::SystemUnderTest class which is defined in system_under_test.h. The QDL implements mlperf::QueryDispatchLibrary class which inherits the mlperf::SystemUnderTest class and has the same API and support all existing mlperf::SystemUnderTest methods. It has a separate header file query_dispatch_library.h. Using sut with mlperf::SystemUnderTest class in LoadGen StartTest is natively upcasting mlperf::QueryDispatchLibrary class.
QDL Query issue and response over the network
The QDL gets the queries from the LoadGen through
void IssueQuery(const std::vector<QuerySample>& samples)
The QDL dispatches the queries to the SUT over the physical media. The exact method and implementation for it are submitter specific and would not be specified at MLCommons. Submitter implementation includes all methods required to serialize the query, load balance, drive it to the Operating system and network interface card and send to the SUT.
The QDL receives the query responses over the network from the SUT. The exact method and implementation for it are submitter specific and would not be specified at MLCommons. The submitter implementation includes all methods required to receive the network data from the Network Interface card, go through the Operating system, deserialize the query response, and provide it back to the LoadGen through query completion by:
struct QuerySampleResponse {
ResponseId id;
uintptr_t data;
size_t size;
};
void QuerySamplesComplete(QuerySampleResponse* responses,
size_t response_count);
QDL Additional Methods
In addition to that the QDL needs to implement the following methods that are provided by the SUT interface to the LoadGen:
const std::string& Name();
The Name function returns a known string for over the Network SUTs to identify it as over the network benchmark.
void FlushQueries();
It is not specified here how the QDL would query and configure the SUT to execute the above methods. The QDL responds to the LoadGen after receiving its own response from the SUT.
Example
Refer to LON demo for a reference example illustrating usage of Loadgen over the network.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file mlcommons_loadgen-4.0.1.tar.gz.
File metadata
- Download URL: mlcommons_loadgen-4.0.1.tar.gz
- Upload date:
- Size: 75.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.9.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 0e7059b289ea2aabb3e9ad1179bbce89703294570ee59c07cf30d52f1b38f732 |
|
| MD5 | 2dce499688f9e7a901c509c4e7ec54d8 |
|
| BLAKE2b-256 | b0fc83d26c14a213adc2a7cf068ce853b841b23a91fcf62216013db6cd858731 |







