A Python library for defining, managing, and executing function pipelines.

Project description
pipefunc: function composition magic for Python
Lightweight function pipeline creation: 📚 Less Bookkeeping, 🎯 More Doing










:books: Table of Contents
- :thinking: What is this?
- :rocket: Key Features
- :test_tube: How does it work?
- :notebook: Jupyter Notebook Example
- :computer: Installation
- :hammer_and_wrench: Development
:thinking: What is this?
pipefunc is a Python library for creating and running function pipelines. By annotating functions and specifying their outputs, it forms a pipeline that automatically organizes the execution order to satisfy dependencies. Just specify the names of the outputs you want to compute, and pipefunc will handle the rest by leveraging the parameter names of the annotated functions.
Whether you're working with data processing, scientific computations, machine learning (AI) workflows, or any other scenario involving interdependent functions, pipefunc helps you focus on the logic of your code while it handles the intricacies of function dependencies and execution order.
:rocket: Key Features
- 🚀 Function Composition and Pipelining: Create pipelines by using the
@pipefuncdecorator; execution order is automatically handled. - 📊 Pipeline Visualization: Generate visual graphs of your pipelines to better understand the flow of data.
- 👥 Multiple Outputs: Handle functions that return multiple results, allowing each result to be used as input to other functions.
- 🔁 Map-Reduce Support: Perform "map" operations to apply functions over data and "reduce" operations to aggregate results, allowing n-dimensional mappings.
- ➡️ Pipeline Simplification: Merge nodes in complex pipelines to run multiple functions in a single step.
- 🎛️ Resource Usage Profiling: Get reports on CPU usage, memory consumption, and execution time to identify bottlenecks and optimize your code.
- 🔄 Automatic parallelization: Automatically runs pipelines in parallel (local or remote) with shared memory and disk caching options.
- 🔍 Parameter Sweep Utilities: Generate parameter combinations for parameter sweeps and optimize the sweeps with result caching.
- 💡 Flexible Function Arguments: Call functions with different argument combinations, letting
pipefuncdetermine which other functions to call based on the provided arguments. - 🏗️ Leverages giants: Builds on top of NetworkX for graph algorithms, NumPy for multi-dimensional arrays, and optionally Xarray for labeled multi-dimensional arrays, Zarr to store results in memory/disk/cloud or any key-value store, and Adaptive for parallel sweeps.
- 🤓 Nerd stats: >400 tests with 100% test coverage, fully typed, only 4 required dependencies, all Ruff Rules, all public API documented.
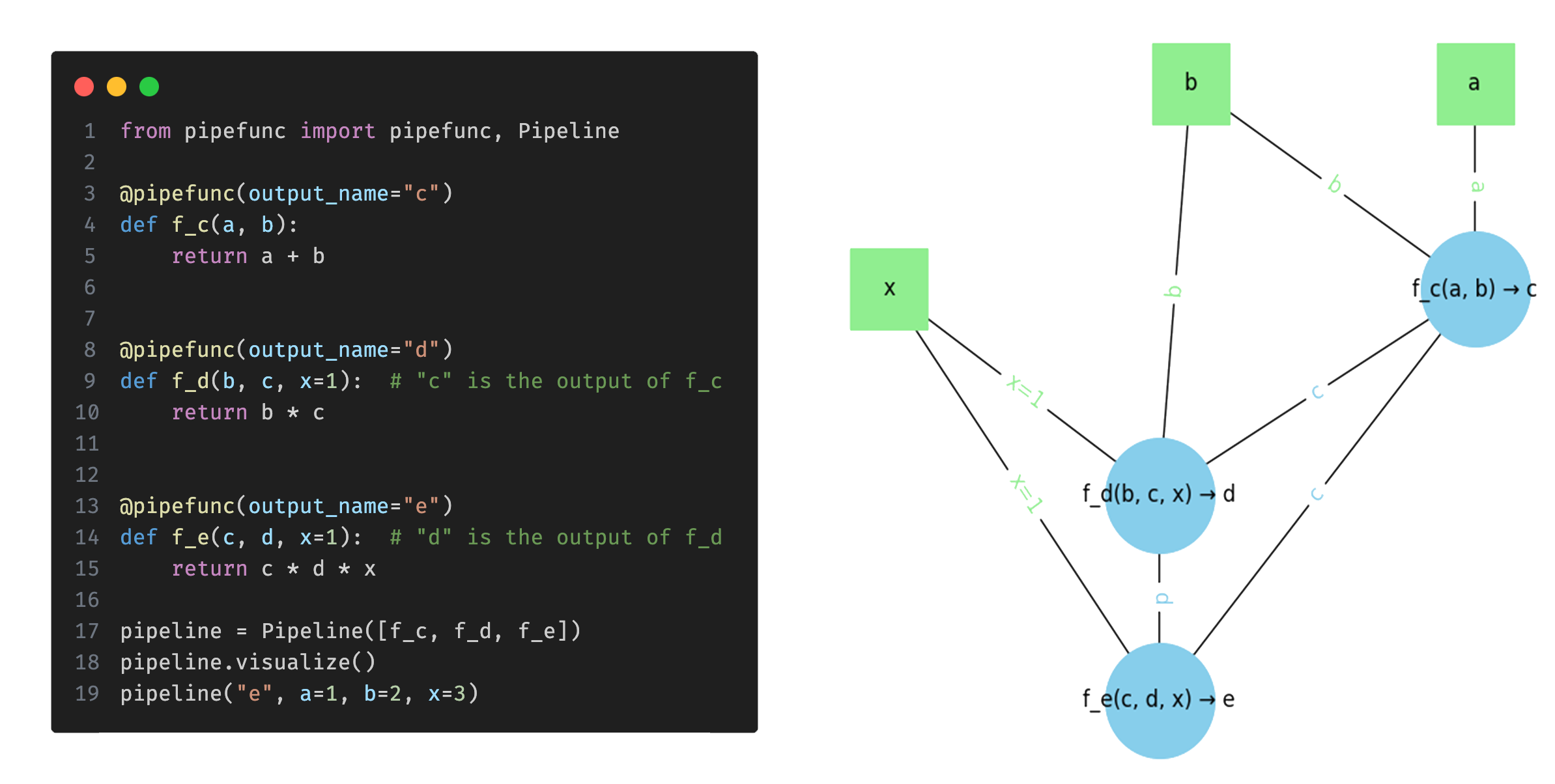
:test_tube: How does it work?
pipefunc provides a Pipeline class that you use to define your function pipeline.
You add functions to the pipeline using the pipefunc decorator, which also lets you specify the function's output name.
Once your pipeline is defined, you can execute it for specific output values, simplify it by combining function nodes, visualize it as a directed graph, and profile the resource usage of the pipeline functions.
For more detailed usage instructions and examples, please check the usage example provided in the package.
Here is a simple example usage of pipefunc to illustrate its primary features:
from pipefunc import pipefunc, Pipeline
# Define three functions that will be a part of the pipeline
@pipefunc(output_name="c")
def f_c(a, b):
return a + b
@pipefunc(output_name="d")
def f_d(b, c):
return b * c
@pipefunc(output_name="e")
def f_e(c, d, x=1):
return c * d * x
# Create a pipeline with these functions
pipeline = Pipeline([f_c, f_d, f_e], profile=True) # `profile=True` enables resource profiling
# Call the pipeline directly for different outputs:
assert pipeline("d", a=2, b=3) == 15
assert pipeline("e", a=2, b=3, x=1) == 75
# Or create a new function for a specific output
h_d = pipeline.func("d")
assert h_d(a=2, b=3) == 15
h_e = pipeline.func("e")
assert h_e(a=2, b=3, x=1) == 75
# Instead of providing the root arguments, you can also provide the intermediate results directly
assert h_e(c=5, d=15, x=1) == 75
# Visualize the pipeline
pipeline.visualize()
# Get all possible argument mappings for each function
all_args = pipeline.all_arg_combinations
print(all_args)
# Show resource reporting (only works if profile=True)
pipeline.print_profiling_stats()
This example demonstrates defining a pipeline with f_c, f_d, f_e functions, accessing and executing these functions using the pipeline, visualizing the pipeline graph, getting all possible argument mappings, and reporting on the resource usage.
This basic example should give you an idea of how to use pipefunc to construct and manage function pipelines.
The following example demonstrates how to perform a map-reduce operation using pipefunc:
from pipefunc import pipefunc, Pipeline
from pipefunc.map import load_outputs
import numpy as np
@pipefunc(output_name="c", mapspec="a[i], b[j] -> c[i, j]") # the mapspec is used to specify the mapping
def f(a: int, b: int):
return a + b
@pipefunc(output_name="mean") # there is no mapspec, so this function takes the full 2D array
def g(c: np.ndarray):
return np.mean(c)
pipeline = Pipeline([f, g])
inputs = {"a": [1, 2, 3], "b": [4, 5, 6]}
pipeline.map(inputs, run_folder="my_run_folder", parallel=True)
result = load_outputs("mean", run_folder="my_run_folder")
print(result) # prints 7.0
Here the mapspec argument is used to specify the mapping between the inputs and outputs of the f function, it creates the product of the a and b input lists and computes the sum of each pair. The g function then computes the mean of the resulting 2D array. The map method executes the pipeline for the inputs, and the load_outputs function is used to load the results of the g function from the specified run folder.
:notebook: Jupyter Notebook Example
See the detailed usage example and more in our example.ipynb.
:computer: Installation
Install the latest stable version from conda (recommended):
conda install pipefunc
or from PyPI:
pip install "pipefunc[all]"
or install main with:
pip install -U https://github.com/pipefunc/pipefunc/archive/main.zip
or clone the repository and do a dev install (recommended for dev):
git clone git@github.com:pipefunc/pipefunc.git
cd pipefunc
pip install -e ".[dev]"
:hammer_and_wrench: Development
We use pre-commit to manage pre-commit hooks, which helps us ensure that our code is always clean and compliant with our coding standards.
To set it up, install pre-commit with pip and then run the install command:
pip install pre-commit
pre-commit install
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
File details
Details for the file pipefunc-0.22.2.tar.gz.
File metadata
- Download URL: pipefunc-0.22.2.tar.gz
- Upload date:
- Size: 102.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/5.1.0 CPython/3.12.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 17b5a34ae49dc1d85fad07a055dadd63e2e055c2af48ce1a58247b71e024f5e2 |
|
| MD5 | ad7d62f769c1da107c11cb6a18086c4f |
|
| BLAKE2b-256 | fb2dc6e2f22ee3f6043665f5b4aca7773a1ecbc3242897be6f7a1efffd52b7b5 |
File details
Details for the file pipefunc-0.22.2-py3-none-any.whl.
File metadata
- Download URL: pipefunc-0.22.2-py3-none-any.whl
- Upload date:
- Size: 90.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/5.1.0 CPython/3.12.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | b147c612b4a3ed6c8b63b561ff47c86f378dfc24846373ad7042acc345c80197 |
|
| MD5 | c3811e2c281854165ac5c8a9f35a4924 |
|
| BLAKE2b-256 | 42f59bf1f4445aeda54526d15134b3b8d9ca0ec371810d9998938005d7ece07b |







