Pipeline Profiler tool. Enables the exploration of D3M pipelines in Jupyter Notebooks


Project description
PipelineProfiler
AutoML Pipeline exploration tool compatible with Jupyter Notebooks. Supports auto-sklearn and D3M pipeline format.

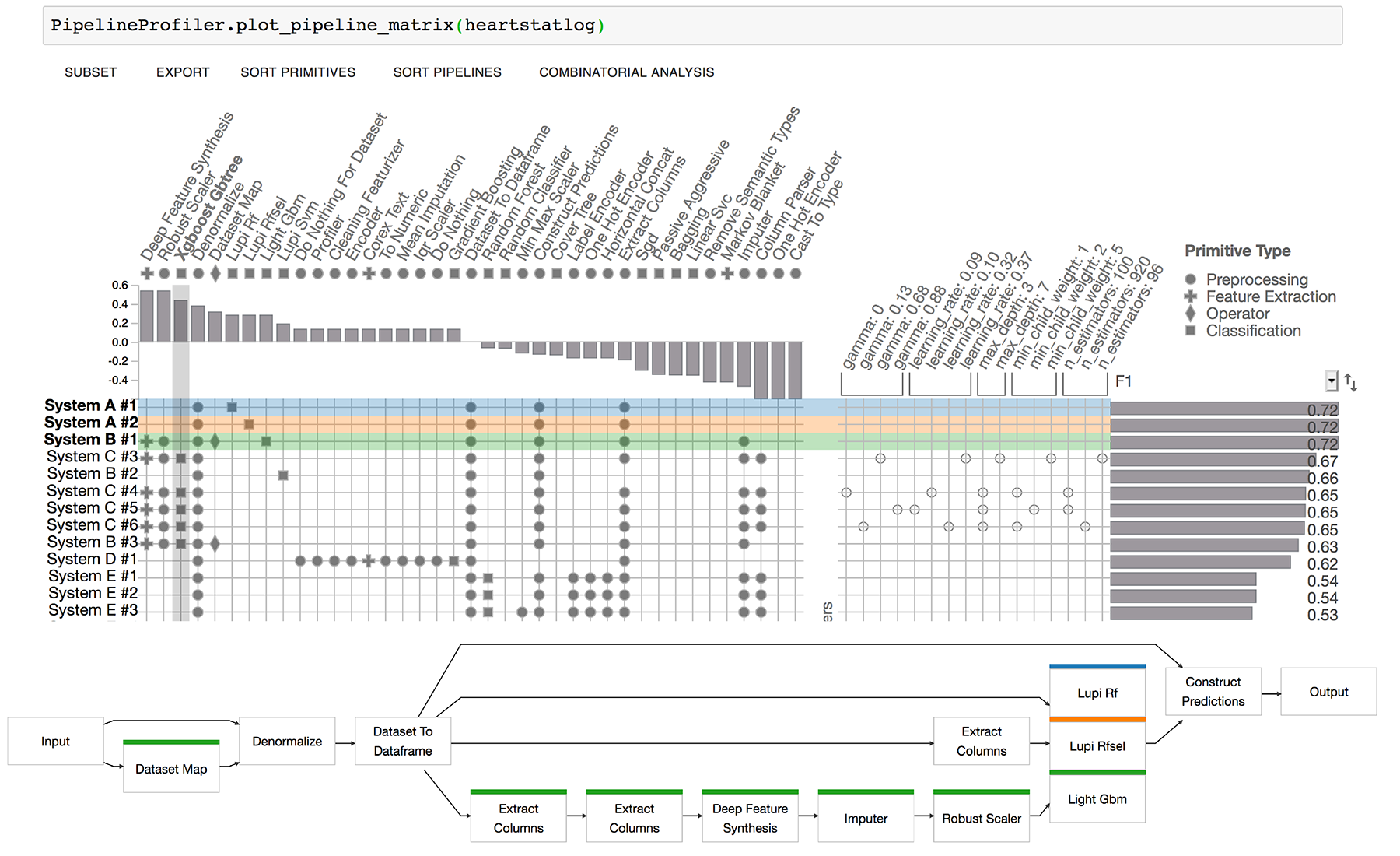
(Shift click to select multiple pipelines)
Paper: https://arxiv.org/abs/2005.00160
Video: https://youtu.be/2WSYoaxLLJ8
Blog: Medium post
Demo
Live demo (Google Colab):
In Jupyter Notebook:
import PipelineProfiler
data = PipelineProfiler.get_heartstatlog_data()
PipelineProfiler.plot_pipeline_matrix(data)
Install
Option 1: install via pip:
pip install pipelineprofiler
Option 2: Run the docker image:
docker build -t pipelineprofiler .
docker run -p 9999:8888 pipelineprofiler
Then copy the access token and log in to jupyter in the browser url:
localhost:9999
Data preprocessing
PipelineProfiler reads data from the D3M Metalearning database. You can download this data from: https://metalearning.datadrivendiscovery.org/dumps/2020/03/04/metalearningdb_dump_20200304.tar.gz
You need to merge two files in order to explore the pipelines: pipelines.json and pipeline_runs.json. To do so, run
python -m PipelineProfiler.pipeline_merge [-n NUMBER_PIPELINES] pipeline_runs_file pipelines_file output_file
Pipeline exploration
import PipelineProfiler
import json
In a jupyter notebook, load the output_file
with open("output_file.json", "r") as f:
pipelines = json.load(f)
and then plot it using:
PipelineProfiler.plot_pipeline_matrix(pipelines[:10])
Data postprocessing
You might want to group pipelines by problem type, and select the top k pipelines from each team. To do so, use the code:
def get_top_k_pipelines_team(pipelines, k):
team_pipelines = defaultdict(list)
for pipeline in pipelines:
source = pipeline['pipeline_source']['name']
team_pipelines[source].append(pipeline)
for team in team_pipelines.keys():
team_pipelines[team] = sorted(team_pipelines[team], key=lambda x: x['scores'][0]['normalized'], reverse=True)
team_pipelines[team] = team_pipelines[team][:k]
new_pipelines = []
for team in team_pipelines.keys():
new_pipelines.extend(team_pipelines[team])
return new_pipelines
def sort_pipeline_scores(pipelines):
return sorted(pipelines, key=lambda x: x['scores'][0]['value'], reverse=True)
pipelines_problem = {}
for pipeline in pipelines:
problem_id = pipeline['problem']['id']
if problem_id not in pipelines_problem:
pipelines_problem[problem_id] = []
pipelines_problem[problem_id].append(pipeline)
for problem in pipelines_problem.keys():
pipelines_problem[problem] = sort_pipeline_scores(get_top_k_pipelines_team(pipelines_problem[problem], k=100))
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
File details
Details for the file pipelineprofiler-0.1.18.tar.gz.
File metadata
- Download URL: pipelineprofiler-0.1.18.tar.gz
- Upload date:
- Size: 871.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/32.0 requests/2.26.0 requests-toolbelt/0.9.1 urllib3/1.26.8 tqdm/4.49.0 importlib-metadata/4.11.1 keyring/23.5.0 rfc3986/2.0.0 colorama/0.4.4 CPython/3.8.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 1e14ed6ed8a08e0726853c4841263411a566d2dcef44624dfa02ecf6ce264432 |
|
| MD5 | a69147df0bc3d8f11e0712a0503c331c |
|
| BLAKE2b-256 | 4639204e9f0a7fde560e178dd82d987b747d450a0521b5b4db4bf1d9792ece4d |
File details
Details for the file pipelineprofiler-0.1.18-py3-none-any.whl.
File metadata
- Download URL: pipelineprofiler-0.1.18-py3-none-any.whl
- Upload date:
- Size: 881.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/32.0 requests/2.26.0 requests-toolbelt/0.9.1 urllib3/1.26.8 tqdm/4.49.0 importlib-metadata/4.11.1 keyring/23.5.0 rfc3986/2.0.0 colorama/0.4.4 CPython/3.8.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 6efe8bfe0bdfbe153d34f27d9c8100c5d02a67fd825591faed5170137011d9d9 |
|
| MD5 | 05196d855613f0ff8833028b8d8c8c98 |
|
| BLAKE2b-256 | 6ec198c22e87afba0a74248632c8b93277b1069083ce580c38edc91c6ecaa30a |







