A Cobertura coverage parser that can diff reports and show coverage progress.

Project description
pycobertura
A Cobertura coverage parser that can diff reports and show coverage progress.


About
pycobertura is a generic Cobertura report parser. It was also designed to help prevent code coverage from decreasing with the pycobertura diff command: any line changed should be tested and uncovered changes should be clearly visible without letting legacy uncovered code get in the way so developers can focus solely on their changes.
Features:
show coverage summary of a cobertura file
output in plain text or HTML
compare two cobertura files and show changes in coverage
colorized diff output
diff exit status of non-zero if coverage worsened or if any changes were left uncovered
fail based on uncovered lines rather than on decrease of coverage rate (see why)
NOTE: The API is unstable any may be subject to changes until it reaches 1.0.
Install
$ pip install pycobertura
CLI usage
pycobertura provides a command line interface to report on coverage files.
Help commands
Different help screens are available depending on what you need help about.
$ pycobertura --help $ pycobertura show --help $ pycobertura diff --help
Command show
The show command displays the report summary of a coverage file.
$ pycobertura show coverage.xml Filename Stmts Miss Cover Missing ------------------------- ------- ------ ------- --------- pycobertura/__init__.py 1 0 100.00% pycobertura/cli.py 18 0 100.00% pycobertura/cobertura.py 93 0 100.00% pycobertura/reporters.py 129 0 100.00% pycobertura/utils.py 12 0 100.00% TOTAL 253 0 100.00%
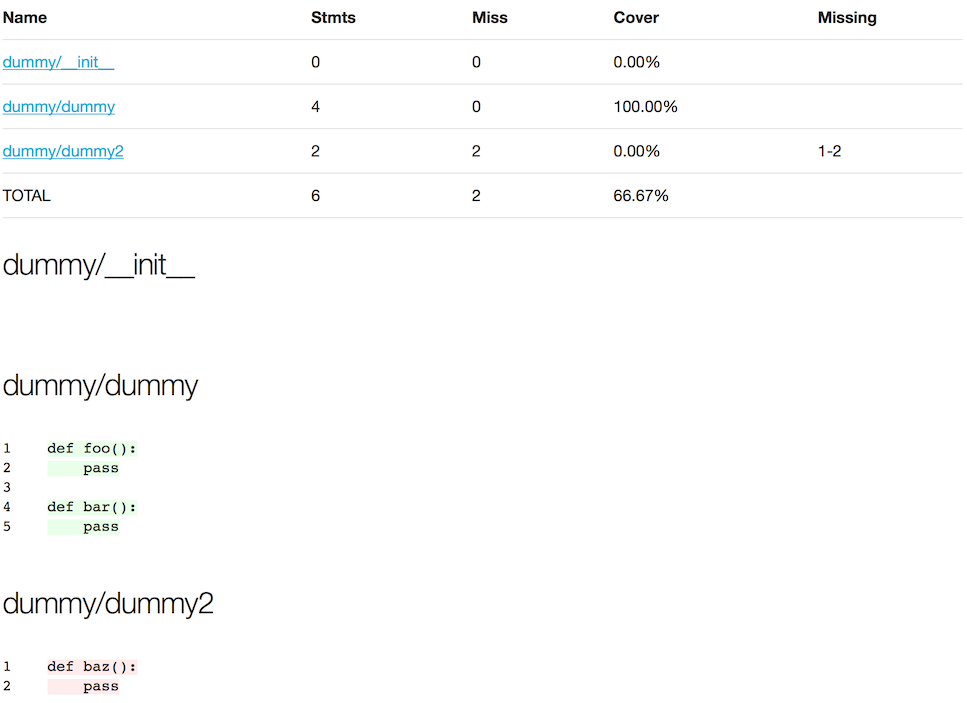
The following is a screenshot of the HTML version of another coverage file which also include the source code with highlighted source code to indicate whether lines were covered (green) or not (red).
pycobertura show --format html --output coverage.html coverage.xml
Command diff
You can also use the diff command to show the difference between two coverage files. To properly compute the Missing column, it is necessary to provide the source code that was used to generate each of the passed Cobertura reports (see why).
$ pycobertura diff coverage.old.xml coverage.new.xml --source1 old_source/ --source2 new_source/ Filename Stmts Miss Cover Missing ---------------- ------- ------ -------- --------- dummy/dummy.py - -2 +50.00% -2, -5 dummy/dummy2.py +2 - +100.00% TOTAL +2 -2 +50.00%
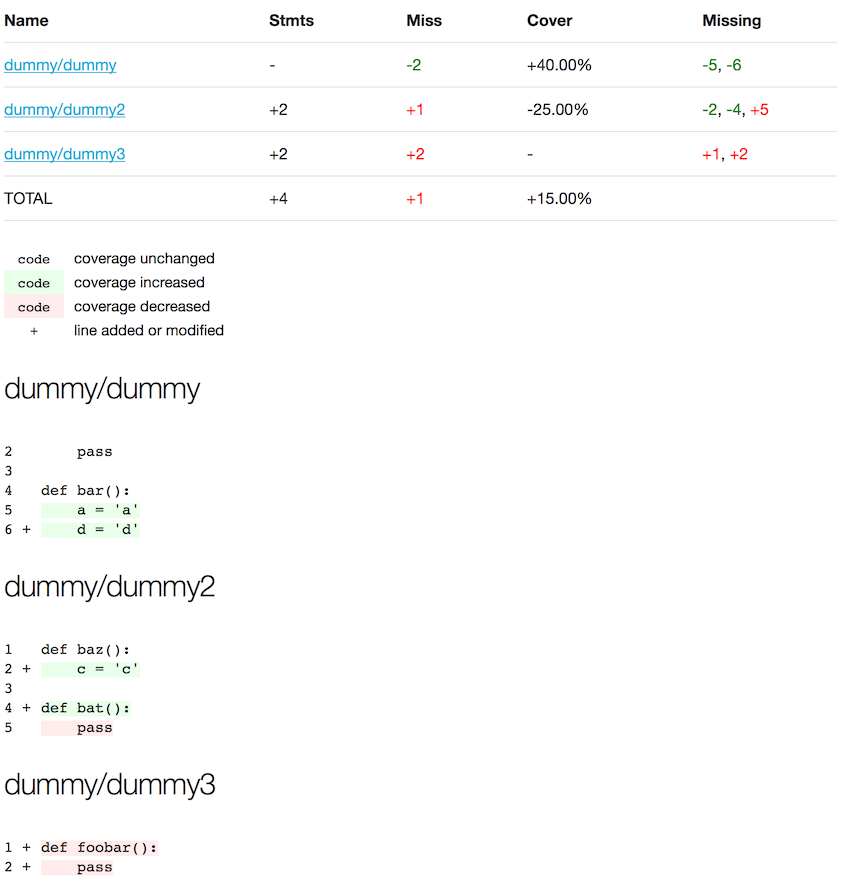
The column Missing will show line numbers prefixed with either a plus sign + or a minus sign -. When prefixed with a plus sign, the line was introduced as uncovered and is shown in red, when prefixed as a minus sign, the line is no longer uncovered and is rendered in green.
This screenshot shows how the HTML output only applies coverage highlighting to the parts of the code where the coverage has changed (from covered to uncovered, or vice versa).
pycobertura diff --format html --output coverage.html ./master/coverage.xml ./myfeature/coverage.xml
diff exit codes
Upon exit, the diff command may return various exit codes:
0: all is good
1: some exception occurred (likely due to inappropriate usage or a bug in pycobertura)
2: coverage worsened (implies 3)
3: not all changes are covered
Library usage
Using it as a library in your Python application is easy:
from pycobertura import Cobertura
cobertura = Cobertura('coverage.xml')
cobertura.version == '4.0.2'
cobertura.line_rate() == 1.0 # 100%
cobertura.files() == [
'pycobertura/__init__.py',
'pycobertura/cli.py',
'pycobertura/cobertura.py',
'pycobertura/reporters.py',
'pycobertura/utils.py',
]
cobertura.line_rate('pycobertura/cli.py') == 1.0
from pycobertura import TextReporter
tr = TextReporter(cobertura)
tr.generate() == """\
Filename Stmts Miss Cover Missing
------------------------- ------- ------ ------- ---------
pycobertura/__init__.py 1 0 100.00%
pycobertura/cli.py 18 0 100.00%
pycobertura/cobertura.py 93 0 100.00%
pycobertura/reporters.py 129 0 100.00%
pycobertura/utils.py 12 0 100.00%
TOTAL 253 0 100.00%"""
from pycobertura import TextReporterDelta
coverage1 = Cobertura('coverage1.xml')
coverage2 = Cobertura('coverage2.xml')
delta = TextReporterDelta(coverage1, coverage2)
delta.generate() == """\
Filename Stmts Miss Cover Missing
---------------- ------- ------ -------- ---------
dummy/dummy.py - -2 +50.00% -2, -5
dummy/dummy2.py +2 - +100.00%
TOTAL +2 -2 +50.00%"""How to contribute?
Found a bug/typo? Got a patch? Have an idea? Please use Github issues or fork pycobertura and submit a pull request (PR). All contributions are welcome!
If you submit a PR:
ensure the description of your PR illustrates your changes clearly by showing what the problem was and how you fixed it (before/after)
make sure your changes are covered with one or more tests
add a descriptive note in the CHANGES file under the Unreleased section
update the README accordingly if your changes outdate the documentation
make sure all tests are passing using tox
pip install tox tox
FAQ
Isn’t pycobertura the same tool as diff-cover?
Diff-cover is a fantastic tool and pycobertura was heavily inspired by it. Both tools have similar end-goals indeed but each tool takes a different approach to how they work.
Diff-cover uses the underlying git repository to find of lines of code that have changed (basically git diff) and then looks at the Cobertura report to check whether the lines in the diff are covered or not. The drawback of this approach is that if the changes introduced a coverage drop elsewhere in the code base (e.g. a legacy function no longer being called) then it can be very hard to hunt down where the coverage dropped, especially if there are already a lot of legacy uncovered lines in the mix.
On the other hand, pycobertura takes two different Cobertura reports in their entirety and compares them line by line. If the coverage status of a line changed from covered to uncovered or vice versa, then pycobertura will report it regardless of where your code changes happened. Actually, sometimes you have no code changes at all, the only changes were to add more tests and pycobertura will show you the progress.
Moreover, pycobertura was also designed as a general purpose Cobertura parser and can generate a summary table for a single Cobertura file (the show command).
I only have one Cobertura report and I just want to see my uncovered changes, can I do this?
Yes, this is what diff-cover already offers and you can achieve the same result with pycobertura. All you have to do is pass your same coverage report twice and provide the path to the two different code bases:
pycobertura diff coverage.xml coverage.xml --source1 master/ --source2 myfeature/But keep in mind that this will not show you if your changes have introduced a drop in coverage elsewhere in the code base. See the previous question about the drawbacks of diff-cover.
Why doesn’t pycobertura use git to diff the source given revision SHAs rather than passing paths to the source code?
Because we would have to support N version control systems (VCS). It is easy enough to generate a directory that contains the source code at a given commit or branch name that it’s not a top priority for pycobertura to be VCS-aware:
git archive --prefix=source1/ ${BRANCH_OR_COMMIT1} | tar -xf -
git archive --prefix=source2/ ${BRANCH_OR_COMMIT2} | tar -xf -
pycobertura diff --source1 source1/ --source2 source2/ coverage1.xml coverage2.xml -o output.html
rm -rf source1/ source2/Mercurial has hg archive and Subversion has svn export. These are simple pre-steps to running pycobertura diff.
Also, the code repository may not always be available at the time pycobertura is run. Typically, in Continous Delivery pipelines, only artifacts are available.
Why do I need to provide the path to the source code directory?
With the command pycobertura show, you don’t need to provide the source code directory, unless you want the HTML output which will conveniently render the highlighted source code for you.
But with pycobertura diff, if you care about which lines are covered or uncovered (and not just a global count), then you will need to provide the source for each of the reports.
To better understand why, let’s assume we have 2 Cobertura reports with the following info:
Report A:
line 1, hit line 2, miss line 3, hit
and Report B:
line 1, hit line 2, miss line 3, hit line 4, miss line 5, hit
How can you tell which lines need to be highlighted? Naively, you’d assume that lines 4-5 were added and these should be the highlighted lines, the ones part of your coverage diff. Well, that doesn’t quite work.
The code for Report A is:
if foo is True: # line 1
total += 1 # line 2
return total # line 3The code for Report B is:
if foo is False: # line 1 # new line
total -= 1 # line 2 # new line
elif foo is True: # line 3 # modified line
total += 1 # line 4, unchanged
return total # line 5, unchangedThe code change are lines 1-3 and these are the ones you want to highlight. Lines 4-5 don’t need to be highlighted (unless coverage status changed in-between).
So, to accurately highlight the lines that have changed, the coverage reports alone are not sufficient and this is why you need to provide the path to the source that was used to generate each of the Cobertura reports and diff them to see which lines actually changed to report accurate coverage.
When should I use pycobertura?
pycobertura was built as a tool to educate developers about the testing culture in such way that any code change should have one or more tests along with it.
You can use pycobertura in your Continous Integration (CI) or Continous Delivery (CD) pipeline which would fail a build if the code changes worsened the coverage. For example, when a pull request is submitted, the new code should have equal or better coverage than the branch it’s going to be merged into. Or if code navigates through a release pipeline and the new code has worse coverage than what’s already in Production, then the release is aborted.
When a build is triggered by your CI/CD pipeline, each testing stage would typically store an artifact of the source code and another one of the Cobertura report. An extra stage in the pipeline could ensure that the coverage did not worsen. This can be done by retrieving the artifacts of the current build as well as the “target” artifacts (code and Cobertura report of Production or target branch of a pull request). Then pycobertura diff will take care of failing the build if the coverage worsened (return a non-zero exit code) and then the pycobertura report can be published as an artifact to make it available to developers to look at.
The step could look like this:
# Download artifacts of current build
curl -o coverage.${BUILD_ID}.xml https://ciserver/artifacts/${BUILD_ID}/coverage.xml
curl -o source.${BUILD_ID}.zip https://ciserver/artifacts/${BUILD_ID}/source.zip
# Download artifacts of already-in-Prod build
curl -o coverage.${PROD_BUILD}.xml https://ciserver/artifacts/${PROD_BUILD}/coverage.xml
curl -o source.${PROD_BUILD}.zip https://ciserver/artifacts/${PROD_BUILD}/source.zip
unzip source.${BUILD_ID}.zip -d source.${BUILD_ID}
unzip source.${PROD_BUILD}.zip -d source.${PROD_BUILD}
# Compare
pycobertura diff --format html \
--output pycobertura-diff.${BUILD_ID}.html \
--source1 source.${PROD_BUILD} \
--source2 source.${BUILD_ID} \
coverage.${PROD_BUILD}.xml \
coverage.${BUILD_ID}.xml
# Upload the pycobertura report artifact
curl -F filedata=@pycobertura-diff.${BUILD_ID}.html http://ciserver/artifacts/${BUILD_ID}/Why is the number of uncovered lines used as the metric to check if code coverage worsened rather than the line rate?
The line rate (percentage of covered lines) can legitimately go down for a number of reasons. To illustrate, suppose we have this code coverage report for version A of our code:
line 1: hit line 2: hit line 3: miss line 4: hit line 5: hit
Here, the line rate is 80% and uncovered lines is 1 (miss). Later in version B of our code, we legitimately delete a covered line and the following coverage report is generated:
line 1: hit ### line deleted ### line 2: miss line 3: hit line 4: hit
The line rate decreased from 80% to 75% but uncovered lines is still at 1. In this case, failing the build based on line rate is inappropriate, thus making the line rate the wrong metric to look at when validating coverage.
The basic idea is that a code base may have technical debt of N uncovered lines and you want to prevent N from ever going up.
pycobertura sounds cool, but how to I generate a Cobertura file?
Depending on your programing language, you need to find a tool that measures code coverage and generates a Cobertura report which is an XML representation of your code coverage results.
In Python, coverage.py is a great tool for measuring code coverage and plugins such as pytest-cov for pytest and nosexcover for nose are available to generate Cobertura reports while running tests.
Cobertura is a very common file format available in many testing tools for pretty much all programing languages. pycobertura is language agnostic and should work with reports generated by tools in any language. But it was mostly developped and tested against reports generated with the pytest-cov plugin in Python. If you see issues, please create a ticket.
Release Notes
Unreleased
0.10.1 (2017-12-30)
Drop support for Python 2.6
Fix a IndexError: list index out of range error by being less specific about where to find class elements in the Cobertura report.
0.10.0 (2016-09-27)
BACKWARDS INCOMPATIBLE: when a source file is not found in disk pycobertura will now raise a pycobertura.filesystem.FileSystem.FileNotFound exception instead of an IOError.
possibility to pass a zip archive containing the source code instead of a directory
BACKWARDS INCOMPATIBLE: Rename keyword argument Cobertura(base_path=None) > Cobertura(source=None)
Introduce new keyword argument Cobertura(source_prefix=None)
Fix an IOError / FileNotFound error which happens when the same coverage report is provided twice to pycobertura diff (diff in degraded mode) but the first code base (--source1) is missing a file mentioned in the coverage report.
Fix a rare bug when diffing coverage xml where one file goes from zero lines to non-zero lines.
0.9.0 (2016-01-29)
The coverage report now displays the class’s filename instead of the class’s name, the latter being more subject to different interpretations by coverage tools. This change was done to support coverage.py versions 3.x and 4.x.
BACKWARDS INCOMPATIBLE: removed CoberturaDiff.filename()
BACKWARDS INCOMPATIBLE: removed the term “class” from the API which make it more difficult to reason about. Now preferring “filename”:
Cobertura.line_rate(class_name=None) > Cobertura.line_rate(filename=None)
Cobertura.branch_rate(class_name=None) > Cobertura.branch_rate(filename=None)
Cobertura.missed_statements(class_name) > Cobertura.missed_statements(filename)
Cobertura.hit_statements(class_name) > Cobertura.hit_statements(filename)
Cobertura.line_statuses(class_name) > Cobertura.line_statuses(filename)
Cobertura.missed_lines(class_name) > Cobertura.missed_lines(filename)
Cobertura.class_source(class_name) > Cobertura.file_source(filename)
Cobertura.total_misses(class_name=None) > Cobertura.total_misses(filename=None)
Cobertura.total_hits(class_name=None) > Cobertura.total_hits(filename=None)
Cobertura.total_statements(class_name=None) > Cobertura.total_statements(filename=None)
Cobertura.filepath(class_name) > Cobertura.filepath(filename)
Cobertura.classes() > Cobertura.files()
Cobertura.has_classfile(class_name) > Cobertura.has_file(filename)
Cobertura.class_lines(class_name) > Cobertura.source_lines(filename)
CoberturaDiff.diff_total_statements(class_name=None) > CoberturaDiff.diff_total_statements(filename=None)
CoberturaDiff.diff_total_misses(class_name=None) > CoberturaDiff.diff_total_misses(filename=None)
CoberturaDiff.diff_total_hits(class_name=None) > CoberturaDiff.diff_total_hits(filename=None)
CoberturaDiff.diff_line_rate(class_name=None) > CoberturaDiff.diff_line_rate(filename=None)
CoberturaDiff.diff_missed_lines(class_name) > CoberturaDiff.diff_missed_lines(filename)
CoberturaDiff.classes() > CoberturaDiff.files()
CoberturaDiff.class_source(class_name) > CoberturaDiff.file_source(filename)
CoberturaDiff.class_source_hunks(class_name) > CoberturaDiff.file_source_hunks(filename)
Reporter.get_source(class_name) > Reporter.get_source(filename)
HtmlReporter.get_class_row(class_name) > HtmlReporter.get_class_row(filename)
DeltaReporter.get_source_hunks(class_name) > DeltaReporter.get_source_hunks(filename)
DeltaReporter.get_class_row(class_name) > DeltaReporter.get_file_row(filename)
0.8.0 (2015-09-28)
BACKWARDS INCOMPATIBLE: return different exit codes depending on diff status. Thanks Marc Abramowitz.
0.7.3 (2015-07-23)
a non-zero exit code will be returned if not all changes have been covered. If --no-source is provided then it will only check if coverage has worsened, which is less strict.
0.7.2 (2015-05-29)
memoize expensive methods of Cobertura (lxml/disk)
assume source code is UTF-8
0.7.1 (2015-04-20)
prevent misalignment of source code and line numbers, this would happen when the source is too long causing it to wrap around.
0.7.0 (2015-04-17)
pycobertura diff now renders colors in terminal with Python 2.x (worked for Python 3.x). For this to work we need to require Click 4.0 so that the color auto-detection of Click can be overridden (not possible in Click 3.0)
Introduce Line namedtuple object which represents a line of source code and coverage status.
BACKWARDS INCOMPATIBLE: List of tuples generated or handled by various function now return Line objects (namedtuple) for each line.
add plus sign (+) in front of lines that were added/modified on HTML diff report
upgrade to Skeleton 2.0.4 (88f03612b05f093e3f235ced77cf89d3a8fcf846)
add legend to HTML diff report
0.6.0 (2015-02-03)
expose CoberturaDiff under the pycobertura namespace
pycobertura diff no longer reports unchanged classes
0.5.2 (2015-01-13)
fix incorrect “TOTAL” row counts of the diff command when classes were added or removed from the second report.
0.5.1 (2015-01-08)
Options of pycobertura diff --missed and --no-missed have been renamed to --source and --no-source which will not show the source code nor display missing lines since they cannot be accurately computed without the source.
Optimized xpath syntax for faster class name lookup (~3x)
Colorize total missed statements
pycobertura diff exit code will be non-zero until all changes are covered
0.5.0 (2015-01-07)
pycobertura diff HTML output now only includes hunks of lines that have coverage changes and skips unchanged classes
handle asymmetric presence of classes in the reports (regression introduced in 0.4.0)
introduce CoberturaDiff.diff_missed_lines()
introduce CoberturaDiff.classes()
introduce CoberturaDiff.filename()
introduce Cobertura.filepath() which will return the system path to the file. It uses base_path to resolve the path.
the summary table of pycobertura diff no longer shows classes that are no longer present
Cobertura.filename() now only returns the filename of the class as found in the Cobertura report, any base_path computation is omitted.
Argument xml_source of Cobertura.__init__() is renamed to xml_path and only accepts an XML path because much of the logic involved in source code path resolution is based on the path provided which cannot work with file objects or XML strings.
Rename Cobertura.source -> Cobertura.xml_path
pycobertura diff now takes options --missed (default) or --no-missed to show missed line numbers. If --missed is given, the paths to the source code must be accessible.
0.4.1 (2015-01-05)
return non-zero exit code if uncovered lines rises (previously based on line rate)
0.4.0 (2015-01-04)
rename Cobertura.total_lines() -> Cobertura.total_statements()
rename Cobertura.line_hits() -> Cobertura.hit_statements()
introduce Cobertura.missed_statements()
introduce Cobertura.line_statuses() which returns line numbers for a given class name with hit/miss statuses
introduce Cobertura.class_source() which returns the source code for a given class along with hit/miss status
pycobertura show now includes HTML source
pycobertura show now accepts --source which indicates where the source code directory is located
Cobertura() now takes an optional base_path argument which will be used to resolve the path to the source code by joining the base_path value to the path found in the Cobertura report.
an error is now raised if Cobertura is passed a non-existent XML file path
pycobertura diff now includes HTML source
pycobertura diff now accepts --source1 and --source2 which indicates where the source code directory of each of the Cobertura reports are located
introduce CoberturaDiff used to diff Cobertura objects
argument class_name for Cobertura.total_statements is now optional
argument class_name for Cobertura.total_misses is now optional
argument class_name for Cobertura.total_hits is now optional
0.3.0 (2014-12-23)
update description of pycobertura
pep8-ify
add pep8 tasks for tox and travis
diff command returns non-zero exit code if coverage worsened
Cobertura.branch_rate is now a method that can take an optional class_name argument
refactor internals for improved readability
show classes that contain no lines, e.g. __init__.py
add Cobertura.filename(class_name) to retrieve the filename of a class
fix erroneous reporting of missing lines which was equal to the number of missed statements (wrong because of multiline statements)
0.2.1 (2014-12-10)
fix py26 compatibility by switching the XML parser to lxml which has a more predictible behavior when used across all Python versions.
add Travis CI
0.2.0 (2014-12-10)
apply Skeleton 2.0 theme to html output
add -o / --output option to write reports to a file.
known issue: diffing 2 files with options --format text, --color and --output does not render color under PY2.
0.1.0 (2014-12-03)
add --color and --no-color options to pycobertura diff.
add option -f and --format with output of text (default) and html.
change class naming from report to reporter
0.0.2 (2014-11-27)
MIT license
use pypandoc to convert the long_description in setup.py from Markdown to reStructuredText so pypi can digest and format the pycobertura page properly.
0.0.1 (2014-11-24)
Initial version
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file pycobertura-0.10.1.tar.gz.
File metadata
- Download URL: pycobertura-0.10.1.tar.gz
- Upload date:
- Size: 55.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | a0dc30b7ace65af574cd37b06b51741865d44f53e0bf0e1b3832501bb48650f2 |
|
| MD5 | 101309c555c2c76105ed22e0a4a2316c |
|
| BLAKE2b-256 | 36be7af3086c9f5ef57c4f8d78e05b91abfea42549a9927f3f0f461c8635fa24 |







