python package for s2s forecasts with ai





Project description
s2spy: Boost (sub) seasonal forecasting with AI









A high-level python package integrating expert knowledge and artificial intelligence to boost (sub) seasonal forecasting.
Why s2spy?
Producing reliable sub-seasonal to seasonal (S2S) forecasts with machine learning techniques remains a challenge. Currently, these data-driven S2S forecasts generally suffer from a lack of trust because of:
- Intransparent data processing and poorly reproducible scientific outcomes
- Technical pitfalls related to machine learning-based predictability (e.g. overfitting)
- Black-box methods without sufficient explanation
To tackle these challenges, we build s2spy which is an open-source, high-level python package. It provides an interface between artificial intelligence and expert knowledge, to boost predictability and physical understanding of S2S processes. By implementing optimal data-handling and parallel-computing packages, it can efficiently run across different Big Climate Data platforms. Key components will be explainable AI and causal discovery, which will support the classical scientific interplay between theory, hypothesis-generation and data-driven hypothesis-testing, enabling knowledge-mining from data.
Developing this tool will be a community effort. It helps us achieve trustworthy data-driven forecasts by providing:
- Transparent and reproducible analyses
- Best practices in model verifications
- Understanding the sources of predictability
Installation


To install the latest release of s2spy, do:
python3 -m pip install s2spy
To install the in-development version from the GitHub repository, do:
python3 -m pip install git+https://github.com/AI4S2S/s2spy.git
Configure the package for development and testing
The testing framework used here is pytest. Before running the test, we get a local copy of the source code and install s2spy via the command:
git clone https://github.com/AI4S2S/s2spy.git
cd s2spy
python3 -m pip install -e .
Then, run tests:
python3 -m pytest
Getting started
s2spy provides end-to-end solutions for machine learning (ML) based S2S forecasting.
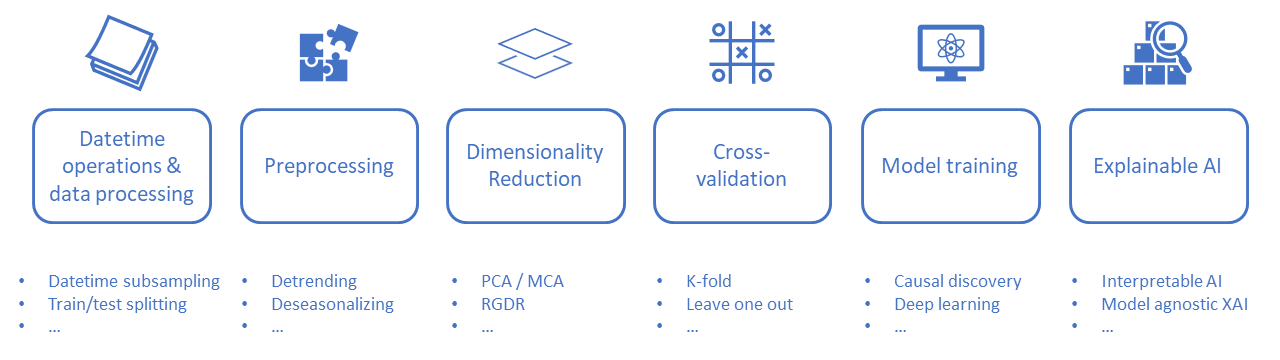
Datetime operations & Data processing
In a typical ML-based S2S project, the first step is always data processing. Our calendar-based package, lilio, is used for time operations. For instance, a user is looking for predictors for winter climate at seasonal timescales (~180 days). First, a Calendar object is created using daily_calendar:
>>> calendar = lilio.daily_calendar(anchor="11-30", length='180d')
>>> calendar = calendar.map_years(2020, 2021)
>>> calendar.show()
i_interval -1 1
anchor_year
2021 [2021-06-03, 2021-11-30) [2021-11-30, 2022-05-29)
2020 [2020-06-03, 2020-11-30) [2020-11-30, 2021-05-29)
Now, the user can load the data input_data (e.g. pandas DataFrame) and resample it to the desired timescales configured in the calendar:
>>> calendar = calendar.map_to_data(input_data)
>>> bins = lilio.resample(calendar, input_data)
>>> bins
anchor_year i_interval interval mean_data target
0 2020 -1 [2020-06-03, 2020-11-30) 275.5 True
1 2020 1 [2020-11-30, 2021-05-29) 95.5 False
2 2021 -1 [2021-06-03, 2021-11-30) 640.5 True
3 2021 1 [2021-11-30, 2022-05-29) 460.5 False
Depending on data preparations, we can choose different types of calendars. For more information, see Lilio's documentation.
Cross-validation
Lilio can also generate train/test splits and perform cross-validation. To do that, a splitter is called from sklearn.model_selection e.g. ShuffleSplit and used to split the resampled data:
from sklearn.model_selection import ShuffleSplit
splitter = ShuffleSplit(n_splits=3)
lilio.traintest.split_groups(splitter, bins)
All splitter classes from scikit-learn are supported, a list is available here. Users should follow scikit-learn documentation on how to use a different splitter class.
Dimensionality reduction
With s2spy, we can perform dimensionality reduction on data. For instance, to perform the Response Guided Dimensionality Reduction (RGDR), we configure the RGDR operator and fit it to a precursor field. Then, this cluster can be used to transform the data into the reduced clusters:
rgdr = RGDR(eps_km=600, alpha=0.05, min_area_km2=3000**2)
rgdr.fit(precursor_field, target_timeseries)
clustered_data = rgdr.transform(precursor_field)
_ = rgdr.plot_clusters(precursor_field, target_timeseries, lag=1)

(for more information about precursor_field and target_timeseries, check the complete example in this notebook.)
Currently, s2spy supports dimensionality reduction approaches from scikit-learn.
Tutorials
s2spy supports operations that are common in a machine learning pipeline of sub-seasonal to seasonal forecasting research. Tutorials covering supported methods and functionalities are listed in notebooks. To check these notebooks, users need to install Jupyter lab. More details about each method can be found in this API reference documentation.
Advanced usecases
You can achieve more by integrating s2spy and lilio into your data-driven S2S forecast workflow! We have a magic cookbook, which includes recipes for complex machine learning based forecasting usecases. These examples will show you how s2spy and lilio can facilitate your workflow.
Documentation
For detailed information on using s2spy package, visit the documentation page hosted at Readthedocs.
Contributing
If you want to contribute to the development of s2spy, have a look at the contribution guidelines.
How to cite us

Please use the Zenodo DOI to cite this package if you used it in your research.
Acknowledgements
This package was developed by the Netherlands eScience Center and Vrije Universiteit Amsterdam. Development was supported by the Netherlands eScience Center under grant number NLESC.OEC.2021.005.
This package was created with Cookiecutter and the NLeSC/python-template.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
File details
Details for the file s2spy-0.4.0.tar.gz.
File metadata
- Download URL: s2spy-0.4.0.tar.gz
- Upload date:
- Size: 5.2 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 4d43b05a26322c10dc63864d6d8d6bdb3ba84899813e4cc6ff9e6591d5abd552 |
|
| MD5 | deab2f15d73990c218992f4aeef00659 |
|
| BLAKE2b-256 | 65a7ceea72d3f8b2f11e15dc4c2d23fbd89fba1bc5af514f550ccb320ce952ef |
File details
Details for the file s2spy-0.4.0-py3-none-any.whl.
File metadata
- Download URL: s2spy-0.4.0-py3-none-any.whl
- Upload date:
- Size: 24.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | a71dfdeb75afcf948b10e46166566f829a755be914efcb60ef5caa360081ddcc |
|
| MD5 | 316c94b3e944e3e43d208bd871fe8070 |
|
| BLAKE2b-256 | d96c52aaf72fdc0d7c7e077c8033a9b013e85a9eb4bfa29b317c6aa9aa0150ce |







