A PydanticV2 validation and serialization libary for the STAC ML Model Extension


Project description
Machine Learning Model Extension Specification

- Title: Machine Learning Model Extension
- Identifier: https://schemas.stacspec.org/2.0.0.alpha.0/extensions/ml-model/json-schema/schema.json
- Field Name Prefix: mlm
- Scope: Item, Collection
- Extension Maturity Classification: Proposal
- Owner:
The STAC Machine Learning Model (MLM) Extension provides a standard set of fields to describe machine learning models trained on overhead imagery and enable running model inference.
The main objectives of the extension are:
- to enable building model collections that can be searched alongside associated STAC datasets
- record all necessary bands, parameters, modeling artifact locations, and high-level processing steps to deploy an inference service.
Specifically, this extension records the following information to make ML models searchable and reusable:
- Sensor band specifications
- Model input transforms including resize and normalization
- Model output shape, data type, and its semantic interpretation
- An optional, flexible description of the runtime environment to be able to run the model
- Scientific references
The MLM specification is biased towards providing metadata fields for supervised machine learning models. However, fields that relate to supervised ML are optional and users can use the fields they need for different tasks.
See Best Practices for guidance on what other STAC extensions you should use in conjunction with this extension. The Machine Learning Model Extension purposely omits and delegates some definitions to other STAC extensions to favor reusability and avoid metadata duplication whenever possible. A properly defined MLM STAC Item/Collection should almost never have the Machine Learning Model Extension exclusively in stac_extensions.
Check the original technical report for an earlier version of the Model Extension, formerly known as the Deep Learning Model Extension (DLM), here for more details. The DLM was renamed to the current MLM Extension and refactored to form a cohesive definition across all machine learning approaches, regardless of whether the approach constitutes a deep neural network or other statistical approach.
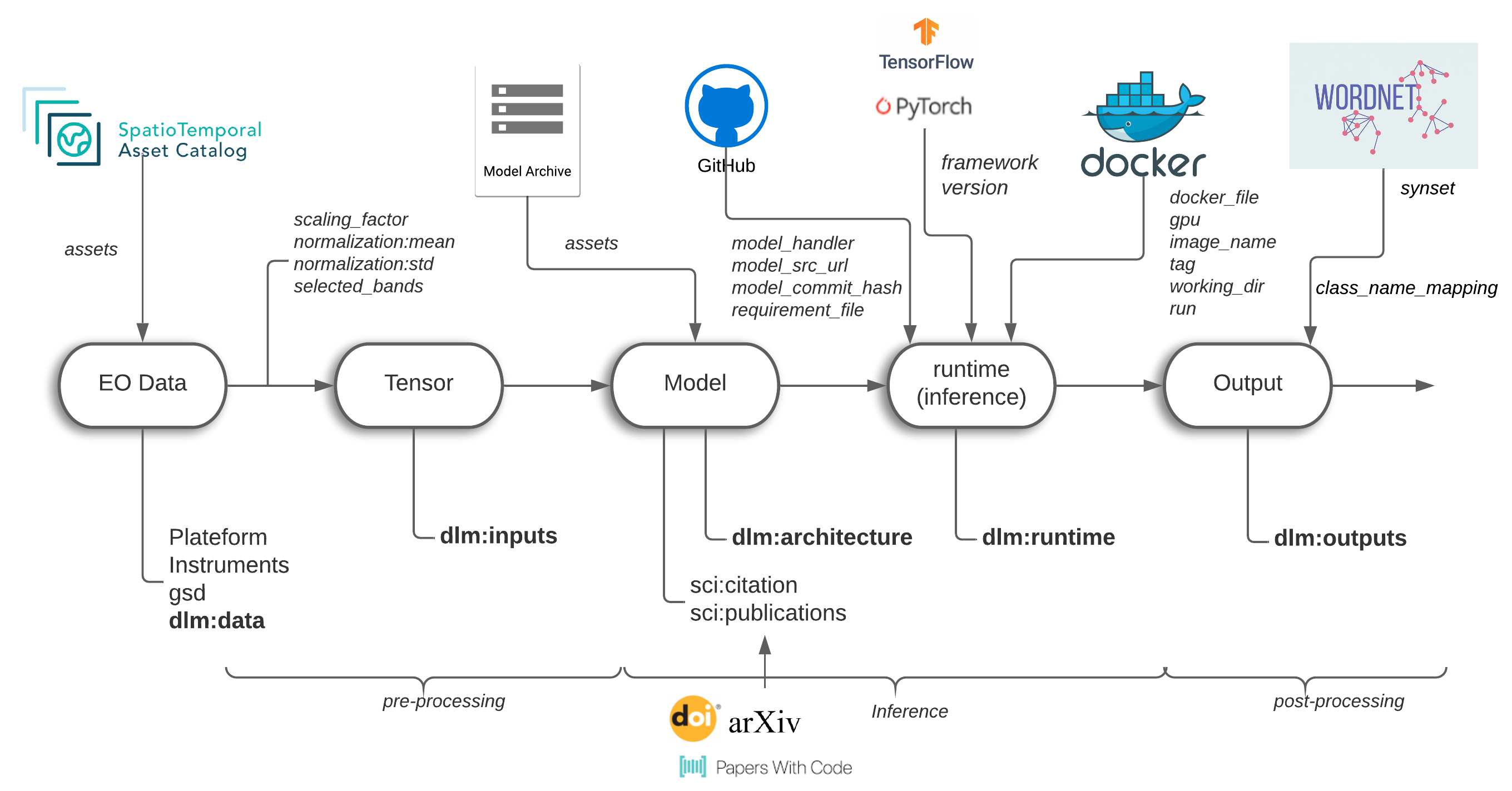
- Examples:
- Example with a ??? trained with torchgeo TODO update example
- Collection example: Shows the basic usage of the extension in a STAC Collection
- JSON Schema TODO update
- Changelog
Item Properties and Collection Fields
| Field Name | Type | Description |
|---|---|---|
| mlm:name | string | REQUIRED. A unique name for the model. This should include but be distinct from simply naming the model architecture. If there is a publication or other published work related to the model, use the official name of the model. |
| mlm:task | Task Enum | REQUIRED. Specifies the primary Machine Learning task for which the output can be used for. If there are multi-modal outputs, specify the primary task and specify each task in the Model Output Object. |
| mlm:framework | string | REQUIRED. Framework used to train the model (ex: PyTorch, TensorFlow). |
| mlm:framework_version | string | REQUIRED. The framework library version. Some models require a specific version of the machine learning framework to run. |
| mlm:file_size | integer | REQUIRED. The size on disk of the model artifact (bytes). |
| mlm:memory_size | integer | REQUIRED. The in-memory size of the model on the accelerator during inference (bytes). |
| mlm:input | [Model Input Object] | REQUIRED. Describes the transformation between the EO data and the model input. |
| mlm:output | [Model Output Object] | REQUIRED. Describes each model output and how to interpret it. |
| mlm:runtime | [Runtime Object] | REQUIRED. Describes the runtime environment(s) to run inference with the model asset(s). |
| mlm:total_parameters | integer | Total number of model parameters, including trainable and non-trainable parameters. |
| mlm:pretrained_source | string | The source of the pretraining. Can refer to popular pretraining datasets by name (i.e. Imagenet) or less known datasets by URL and description. |
| mlm:summary | string | Text summary of the model and it's purpose. |
| mlm:parameters | Parameters Object | Mapping with names for the parameters and their values. Some models may take additional scalars, tuples, and other non-tensor inputs like text during inference (Segment Anything). The field should be specified here if parameters apply to all Model Input Objects. If each Model Input Object has parameters, specify parameters in that object. |
In addition, fields from the following extensions must be imported in the item:
- Scientific Extension Specification to describe relevant publications.
- Version Extension Specification to define version tags.
Model Input Object
| Field Name | Type | Description | |
|---|---|---|---|
| name | string | REQUIRED. Informative name of the input variable. Example "RGB Time Series" | |
| bands | [string] | REQUIRED. The names of the raster bands used to train or fine-tune the model, which may be all or a subset of bands available in a STAC Item's Band Object. | |
| input_array | Array Object | REQUIRED. The N-dimensional array object that describes the shape, dimension ordering, and data type. | |
| parameters | Parameters Object | Mapping with names for the parameters and their values. Some models may take additional scalars, tuples, and other non-tensor inputs like text. | |
| norm_by_channel | boolean | Whether to normalize each channel by channel-wise statistics or to normalize by dataset statistics. If True, use an array of Statistics Objects that is ordered like the bands field in this object. |
|
| norm_type | string | Normalization method. Select one option from "min_max", "z_score", "max_norm", "mean_norm", "unit_variance", "norm_with_clip", "none" | |
| resize_type | string | High-level descriptor of the rescaling method to change image shape. Select one option from "crop", "pad", "interpolation", "none". If your rescaling method combines more than one of these operations, provide the name of the operation instead | |
| statistics | Statistics Object | [Statistics Object] |
Dataset statistics for the training dataset used to normalize the inputs. | |
| norm_with_clip_values | [integer] | If norm_type = "norm_with_clip" this array supplies a value that is less than the band maximum. The array must be the same length as "bands", each value is used to divide each band before clipping values between 0 and 1. | |
| pre_processing_function | string | A url to the preprocessing function where normalization and rescaling takes place, and any other significant operations. Or, instead, the function code path, for example: my_python_module_name:my_processing_function |
Parameters Object
| Field Name | Type | Description |
|---|---|---|
| parameter names depend on the model | number | string | boolean | array |
The number of fields and their names depend on the model. Values should not be n-dimensional array inputs. If the model input can be represented as an n-dimensional array, it should instead be supplied as another model input object. |
The parameters field can either be specified in the Model Input Object if they are associated with a specific input or as an Item or Collection field if the parameters are supplied without relation to a specific model input.
Bands and Statistics
We use the STAC 1.1 Bands Object for representing bands information, including the nodata value, data type, and common band names. Only bands used to train or fine tune the model should be included in this bands field.
A deviation from the STAC 1.1 Bands Object is that we do not include the Statistics object at the band object level, but at the Model Input level. This is because in machine learning, it is common to only need overall statistics for the dataset used to train the model to normalize all bands.
Array Object
| Field Name | Type | Description | |
|---|---|---|---|
| shape | [integer] | REQUIRED. Shape of the input n-dimensional array ($N \times C \times H \times W$), including the batch size dimension. The batch size dimension must either be greater than 0 or -1 to indicate an unspecified batch dimension size. | |
| dim_order | string | REQUIRED. How the above dimensions are ordered within the shape. "bhw", "bchw", "bthw", "btchw" are valid orderings where b=batch, c=channel, t=time, h=height, w=width. |
|
| data_type | enum | REQUIRED. The data type of values in the n-dimensional array. For model inputs, this should be the data type of the processed input supplied to the model inference function, not the data type of the source bands. Use one of the common metadata data types. |
Note: It is common in the machine learning, computer vision, and remote sensing communities to refer to rasters that are inputs to a model as arrays or tensors. Array Objects are distinct from the JSON array type used to represent lists of values.
Runtime Object
| Field Name | Type | Description |
|---|---|---|
| model_asset | Asset Object | REQUIRED. Asset object containing URI to the model file. |
| source_code | Asset Object | REQUIRED. Source code description. Can describe a github repo, zip archive, etc. This description should reference the inference function, for example my_package.my_module.predict |
| accelerator | Accelerator Enum | REQUIRED. The intended computational hardware that runs inference. |
| accelerator_constrained | boolean | REQUIRED. True if the intended accelerator is the only accelerator that can run inference. False if other accelerators, such as amd64 (CPU), can run inference. |
| hardware_summary | string | REQUIRED. A high level description of the number of accelerators, specific generation of the accelerator, or other relevant inference details. |
| container | Container | RECOMMENDED. Information to run the model in a container instance. |
| model_commit_hash | string | Hash value pointing to a specific version of the code. |
| batch_size_suggestion | number | A suggested batch size for the accelerator and summarized hardware. |
Accelerator Enum
It is recommended to define accelerator with one of the following values:
amd64models compatible with AMD or Intel CPUs (no hardware specific optimizations)cudamodels compatible with NVIDIA GPUsxlamodels compiled with XLA. models trained on TPUs are typically compiled with XLA.amd-rocmmodels trained on AMD GPUsintel-ipex-cpufor models optimized with IPEX for Intel CPUsintel-ipex-gpufor models optimized with IPEX for Intel GPUsmacos-armfor models trained on Apple Silicon
Container Object
| Field Name | Type | Description |
|---|---|---|
| container_file | string | Url of the container file (Dockerfile). |
| image_name | string | Name of the container image. |
| tag | string | Tag of the image. |
| working_dir | string | Working directory in the instance that can be mapped. |
| run | string | Running command. |
If you're unsure how to containerize your model, we suggest starting from the latest official container image for your framework that works with your model and pinning the container version.
Examples: Pytorch Dockerhub Pytorch Docker Run Example
Tensorflow Dockerhub Tensorflow Docker Run Example
Using a base image for a framework looks like
# In your Dockerfile, pull the latest base image with all framework dependencies including accelerator drivers
FROM pytorch/pytorch:2.1.2-cuda11.8-cudnn8-runtime
### Your specific environment setup to run your model
RUN pip install my_package
You can also use other base images. Pytorch and Tensorflow offer docker images for serving models for inference.
Model Output Object
| Field Name | Type | Description |
|---|---|---|
| task | Task Enum | REQUIRED. Specifies the Machine Learning task for which the output can be used for. |
| result | [Result Array Object] | The list of output array/tensor from the model. For example ($N \times H \times W$). Use -1 to indicate variable dimensions, like the batch dimension. |
| classification:classes | [Class Object] | A list of class objects adhering to the Classification extension. |
| post_processing_function | string | A url to the postprocessing function where normalization, rescaling, and other operations take place.. Or, instead, the function code path, for example: my_package.my_module.my_processing_function |
While only task is a required field, all fields are recommended for supervised tasks that produce a fixed shape tensor and have output classes.
image-captioning, multi-modal, and generative tasks may not return fixed shape tensors or classes.
Task Enum
It is recommended to define task with one of the following values for each Model Output Object:
regressionclassificationobject detectionsemantic segmentationinstance segmentationpanoptic segmentationmulti-modalsimilarity searchimage captioninggenerativesuper resolution
If the task falls within the category of supervised machine learning and uses labels during training, this should align with the label:tasks values defined in STAC Label Extension for relevant
STAC Collections and Items published with the model described by this extension.
Result Array Object
| Field Name | Type | Description |
|---|---|---|
| shape | [integer] | REQUIRED. Shape of the n-dimensional result array ($N \times H \times W$), possibly including a batch size dimension. The batch size dimension must either be greater than 0 or -1 to indicate an unspecified batch dimension size. |
| dim_names | [string] | REQUIRED. The names of the above dimensions of the result array, ordered the same as this object's shape field. |
| data_type | enum | REQUIRED. The data type of values in the n-dimensional array. For model outputs, this should be the data type of the result of the model inference without extra post processing. Use one of the common metadata data types. |
Class Object
See the documentation for the Class Object. We don't use the Bit Field Object since inputs and outputs to machine learning models don't typically use bit fields.
Relation types
The following types should be used as applicable rel types in the
Link Object of STAC Items describing Band Assets used with a model.
| Type | Description |
|---|---|
| derived_from | This link points to _item.json or _collection.json. Replace with the unique mlm:name field's value. |
Contributing
All contributions are subject to the STAC Specification Code of Conduct. For contributions, please follow the STAC specification contributing guide Instructions for running tests are copied here for convenience.
Running tests
The same checks that run as checks on PRs are part of the repository and can be run locally to verify that changes are valid. To run tests locally, you'll need npm, which is a standard part of any node.js installation.
First, install everything with npm once. Navigate to the root of this repository and on your command line run:
npm install
Then to check Markdown formatting and test the examples against the JSON schema, you can run:
npm test
This will spit out the same texts that you see online, and you can then go and fix your markdown or examples.
If the tests reveal formatting problems with the examples, you can fix them with:
npm run format-examples
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
File details
Details for the file stac_model-0.1.1a3.tar.gz.
File metadata
- Download URL: stac_model-0.1.1a3.tar.gz
- Upload date:
- Size: 24.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.7.1 CPython/3.10.12 Linux/6.5.0-21-generic
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 76a87c905cdf3316663cb878923802c93e49026b304796ae99d99e1407357647 |
|
| MD5 | 3248d2e0850e3494492564d246f06db8 |
|
| BLAKE2b-256 | 617c8f3bc4b36c9fe708b1ef09aa95201531e744576a6a5914e2a978964e08f1 |
Provenance
File details
Details for the file stac_model-0.1.1a3-py3-none-any.whl.
File metadata
- Download URL: stac_model-0.1.1a3-py3-none-any.whl
- Upload date:
- Size: 18.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.7.1 CPython/3.10.12 Linux/6.5.0-21-generic
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 305c13c089971ec4823293f9a19006b300aeacaaaf34d9ed0ad6ffc87525638f |
|
| MD5 | 442442c77e91ee8805615e988b4e9c12 |
|
| BLAKE2b-256 | afe3e777a317e16c04987a9023bc39d8100a12a8657b3384c9b06b9f1b6eed7b |







