A package for converting time series data from e.g. electronic health records into wide format data.

Project description
Timeseriesflattener





Time series from e.g. electronic health records often have a large number of variables, are sampled at irregular intervals and tend to have a large number of missing values. Before this type of data can be used for prediction modelling with machine learning methods such as logistic regression or XGBoost, the data needs to be reshaped. In essence, the time series need to be flattened so that each prediction time is represented by a set of predictor values and an outcome value. These predictor values can be constructed by aggregating the preceding values in the time series within a certain time window. This process lays the foundation for further analyses and requires handling a number of tasks such as 1) how to deal with missing values, 2) which value to use if none fall within the prediction window, and 3) how to handle predictors that attempt to look further back than the start of the dataset.
timeseriesflattener aims to simplify this process by providing an easy-to-use and fully-specified pipeline for flattening complex time series. timeseriesflattener implements all the functionality required for aggregating features in specific time windows, grouped by e.g. patient IDs, in a computationally efficient manner.
🗺️ Roadmap
Roadmap is tracked on our kanban board.
🔧 Installation
To get started using timeseriesflattener simply install it using pip by running the following line in your terminal:
pip install timeseriesflattener
🤖 Functionality
timeseriesflattener includes features required for converting any number of (irregular) time series into a single dataframe with a row for each desired prediction time and columns for each constructed feature. Raw values are aggregated by an ID column, which allows for e.g. aggregating values for each patient independently.
When constructing feature sets from time series in general, or medical time series in particular, there are several choices one needs to make.
- When to issue predictions (prediction time). E.g. at every physical visit, every morning, or another clinically meaningful time.
- How far back/ahead from the prediction times to look for raw values (lookbehind/lookahead).
- Which method to use for aggregation if multiple values exist in the lookbehind.
- Which value to use if there are no data points in the lookbehind.
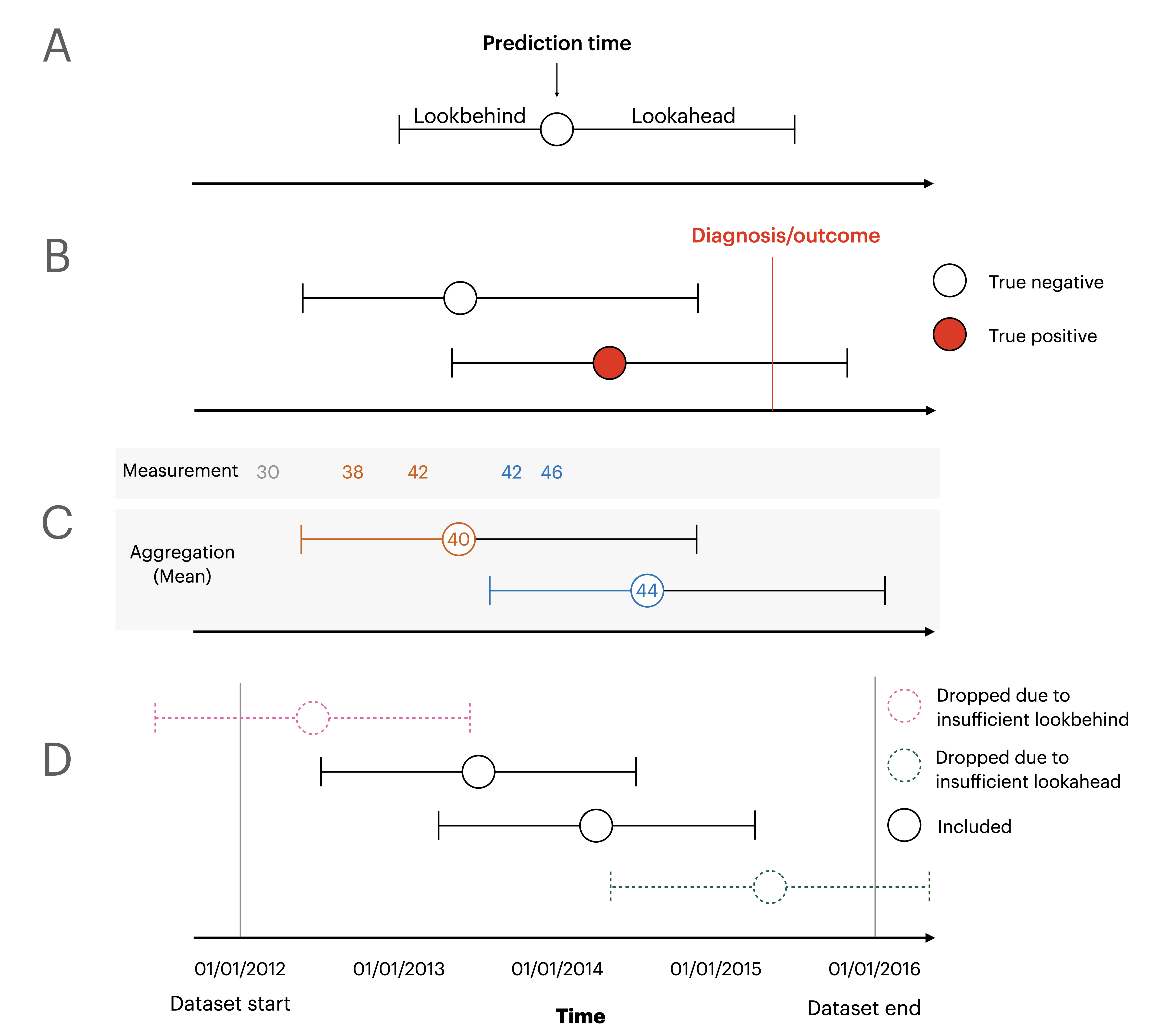
The above figure graphically represents the terminology used in the package. A: Lookbehind determines how far back in time to look for values for predictors, whereas lookahead determines how far into the future to look for outcome values. A prediction time indicates at which point the model issues a prediction, and is used as a reference for the lookbehind and lookahead. B: Labels for prediction times are true negatives if the outcome never occurs, or if the outcome happens outside the lookahead window. Labels are only true positives if the outcome occurs inside the lookahead window. C) Values within the lookbehind window are aggregated using a specified function, for example the mean as shown in this example, or max/min etc. D) Prediction times are dropped if the lookbehind extends further back in time than the start of the dataset or if the lookahead extends further than the end of the dataset. This behaviour is optional.
Multiple lookbehind windows and aggregation functions can be specified for each feature to obtain a rich representation of the data. See the tutorials for example use cases.
⚡ Quick start
import numpy as np
import pandas as pd
if __name__ == "__main__":
# Load a dataframe with times you wish to make a prediction
prediction_times_df = pd.DataFrame(
{
"id": [1, 1, 2],
"date": ["2020-01-01", "2020-02-01", "2020-02-01"],
},
)
# Load a dataframe with raw values you wish to aggregate as predictors
predictor_df = pd.DataFrame(
{
"id": [1, 1, 1, 2],
"date": [
"2020-01-15",
"2019-12-10",
"2019-12-15",
"2020-01-02",
],
"value": [1, 2, 3, 4],
},
)
# Load a dataframe specifying when the outcome occurs
outcome_df = pd.DataFrame({"id": [1], "date": ["2020-03-01"], "value": [1]})
# Specify how to aggregate the predictors and define the outcome
from timeseriesflattener.feature_spec_objects import OutcomeSpec, PredictorSpec
from timeseriesflattener.resolve_multiple_functions import maximum, mean
predictor_spec = PredictorSpec(
values_df=predictor_df,
lookbehind_days=30,
fallback=np.nan,
entity_id_col_name="id",
resolve_multiple_fn=mean,
feature_name="test_feature",
)
outcome_spec = OutcomeSpec(
values_df=outcome_df,
lookahead_days=31,
fallback=0,
entity_id_col_name="id",
resolve_multiple_fn=maximum,
feature_name="test_outcome",
incident=False,
)
# Instantiate TimeseriesFlattener and add the specifications
from timeseriesflattener import TimeseriesFlattener
ts_flattener = TimeseriesFlattener(
prediction_times_df=prediction_times_df,
entity_id_col_name="id",
timestamp_col_name="date",
n_workers=1,
drop_pred_times_with_insufficient_look_distance=False,
)
ts_flattener.add_spec([predictor_spec, outcome_spec])
df = ts_flattener.get_df()
df
Output:
| id | date | prediction_time_uuid | pred_test_feature_within_30_days_mean_fallback_nan | outc_test_outcome_within_31_days_maximum_fallback_0_dichotomous | |
|---|---|---|---|---|---|
| 0 | 1 | 2020-01-01 00:00:00 | 1-2020-01-01-00-00-00 | 2.5 | 0 |
| 1 | 1 | 2020-02-01 00:00:00 | 1-2020-02-01-00-00-00 | 1 | 1 |
| 2 | 2 | 2020-02-01 00:00:00 | 2-2020-02-01-00-00-00 | 4 | 0 |
📖 Documentation
| Documentation | |
|---|---|
| 🎛 API References | The detailed reference for timeseriesflattener's API. Including function documentation |
| 🙋 FAQ | Frequently asked question |
💬 Where to ask questions
| Type | |
|---|---|
| 🚨 Bug Reports | GitHub Issue Tracker |
| 🎁 Feature Requests & Ideas | GitHub Issue Tracker |
| 👩💻 Usage Questions | GitHub Discussions |
| 🗯 General Discussion | GitHub Discussions |
🎓 Projects
PSYCOP projects which use timeseriesflattener. Note that some of these projects have yet to be published and are thus private.
| Project | Publications | |
|---|---|---|
| Type 2 Diabetes | Prediction of type 2 diabetes among patients with visits to psychiatric hospital departments | |
| Cancer | Prediction of Cancer among patients with visits to psychiatric hospital departments | |
| COPD | Prediction of Chronic obstructive pulmonary disease (COPD) among patients with visits to psychiatric hospital departments | |
| Forced admissions | Prediction of forced admissions of patients to the psychiatric hospital departments. Encompasses two seperate projects: 1. Prediciting at time of discharge for inpatient admissions. 2. Predicting day before outpatient admissions. | |
| Coercion | Prediction of coercion among patients admittied to the hospital psychiatric department. Encompasses predicting mechanical restraint, sedative medication and manual restraint 48 hours before coercion occurs. |
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
File details
Details for the file timeseriesflattener-0.20.3.tar.gz.
File metadata
- Download URL: timeseriesflattener-0.20.3.tar.gz
- Upload date:
- Size: 32.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.9.2 readme-renderer/37.3 requests/2.28.1 requests-toolbelt/0.10.1 urllib3/1.26.13 tqdm/4.64.1 importlib-metadata/5.1.0 keyring/23.11.0 rfc3986/2.0.0 colorama/0.4.6 CPython/3.9.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | f52e868addd30d243443b5ccab8645e4d45ec8f9b02b13af012d868d67f17949 |
|
| MD5 | 5ba50bab373d76e1e2bcd362a1f8f4d6 |
|
| BLAKE2b-256 | 4f97ad9e75344eba05bc81b3a4d3e6716926a747c5c39e95f7bb445c17ae41a8 |
File details
Details for the file timeseriesflattener-0.20.3-py3-none-any.whl.
File metadata
- Download URL: timeseriesflattener-0.20.3-py3-none-any.whl
- Upload date:
- Size: 32.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.9.2 readme-renderer/37.3 requests/2.28.1 requests-toolbelt/0.10.1 urllib3/1.26.13 tqdm/4.64.1 importlib-metadata/5.1.0 keyring/23.11.0 rfc3986/2.0.0 colorama/0.4.6 CPython/3.9.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 3bf2d9b1e79d6919a00b44e8b0950b5ffffecdd00ae7fc7a9c9dfce49d4c10b9 |
|
| MD5 | 851ce8b7d5c8d81f83081864d5ed75b0 |
|
| BLAKE2b-256 | 9c0dcd8f7158868434d1e9948d60db4a15ea32fe1441a3b113cbb3503eda4816 |







