A package for converting time series data from e.g. electronic health records into wide format data.

Project description
Timeseriesflattener






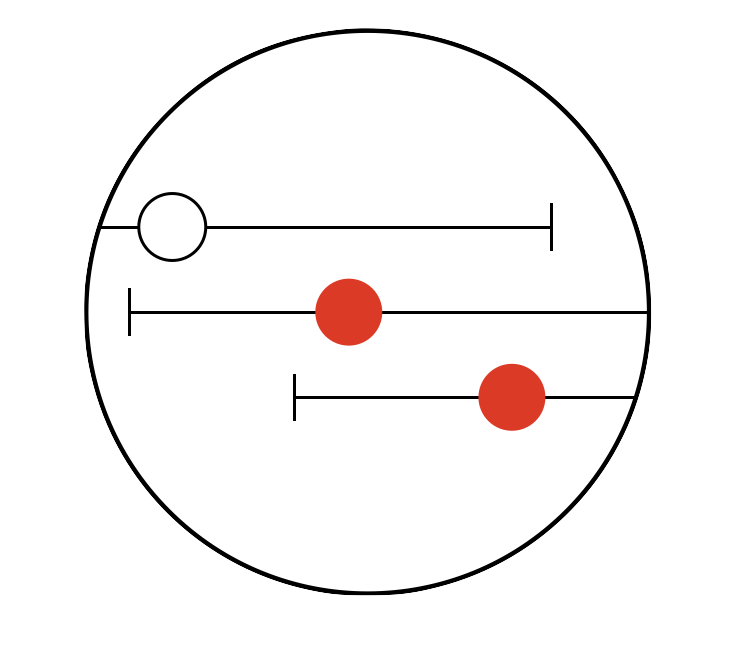
Time series from e.g. electronic health records often have a large number of variables, are sampled at irregular intervals and tend to have a large number of missing values. Before this type of data can be used for prediction modelling with machine learning methods such as logistic regression or XGBoost, the data needs to be reshaped.
In essence, the time series need to be flattened so that each prediction time is represented by a set of predictor values and an outcome value. These predictor values can be constructed by aggregating the preceding values in the time series within a certain time window.
timeseriesflattener aims to simplify this process by providing an easy-to-use and fully-specified pipeline for flattening complex time series.
🔧 Installation
To get started using timeseriesflattener simply install it using pip by running the following line in your terminal:
pip install timeseriesflattener
⚡ Quick start
import numpy as np
import pandas as pd
if __name__ == "__main__":
# Load a dataframe with times you wish to make a prediction
prediction_times_df = pd.DataFrame(
{
"id": [1, 1, 2],
"date": ["2020-01-01", "2020-02-01", "2020-02-01"],
},
)
# Load a dataframe with raw values you wish to aggregate as predictors
predictor_df = pd.DataFrame(
{
"id": [1, 1, 1, 2],
"date": [
"2020-01-15",
"2019-12-10",
"2019-12-15",
"2020-01-02",
],
"value": [1, 2, 3, 4],
},
)
# Load a dataframe specifying when the outcome occurs
outcome_df = pd.DataFrame({"id": [1], "date": ["2020-03-01"], "value": [1]})
# Specify how to aggregate the predictors and define the outcome
from timeseriesflattener.feature_specs.single_specs import OutcomeSpec, PredictorSpec
from timeseriesflattener.aggregation_fns import maximum, mean
predictor_spec = PredictorSpec(
timeseries_df=predictor_df,
lookbehind_days=30,
fallback=np.nan,
aggregation_fn=mean,
feature_base_name="test_feature",
)
outcome_spec = OutcomeSpec(
timeseries_df=outcome_df,
lookahead_days=31,
fallback=0,
aggregation_fn=maximum,
feature_base_name="test_outcome",
incident=False,
)
# Instantiate TimeseriesFlattener and add the specifications
from timeseriesflattener import TimeseriesFlattener
ts_flattener = TimeseriesFlattener(
prediction_times_df=prediction_times_df,
entity_id_col_name="id",
timestamp_col_name="date",
n_workers=1,
drop_pred_times_with_insufficient_look_distance=False,
)
ts_flattener.add_spec([predictor_spec, outcome_spec])
df = ts_flattener.get_df()
df
Output:
| id | date | prediction_time_uuid | pred_test_feature_within_30_days_mean_fallback_nan | outc_test_outcome_within_31_days_maximum_fallback_0_dichotomous | |
|---|---|---|---|---|---|
| 0 | 1 | 2020-01-01 00:00:00 | 1-2020-01-01-00-00-00 | 2.5 | 0 |
| 1 | 1 | 2020-02-01 00:00:00 | 1-2020-02-01-00-00-00 | 1 | 1 |
| 2 | 2 | 2020-02-01 00:00:00 | 2-2020-02-01-00-00-00 | 4 | 0 |
📖 Documentation
| Documentation | |
|---|---|
| 🎓 Tutorial | Simple and advanced tutorials to get you started using timeseriesflattener |
| 🎛 General docs | The detailed reference for timeseriesflattener's API. |
| 🙋 FAQ | Frequently asked question |
| 🗺️ Roadmap | Kanban board for the roadmap for the project |
💬 Where to ask questions
| Type | |
|---|---|
| 🚨 Bug Reports | GitHub Issue Tracker |
| 🎁 Feature Requests & Ideas | GitHub Issue Tracker |
| 👩💻 Usage Questions | GitHub Discussions |
| 🗯 General Discussion | GitHub Discussions |
🎓 Projects
PSYCOP projects which use timeseriesflattener. Note that some of these projects have yet to be published and are thus private.
| Project | Publications | |
|---|---|---|
| Type 2 Diabetes | Prediction of type 2 diabetes among patients with visits to psychiatric hospital departments |
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
File details
Details for the file timeseriesflattener-1.10.0.tar.gz.
File metadata
- Download URL: timeseriesflattener-1.10.0.tar.gz
- Upload date:
- Size: 5.4 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.9.6 readme-renderer/42.0 requests/2.31.0 requests-toolbelt/1.0.0 urllib3/2.1.0 tqdm/4.66.1 importlib-metadata/7.0.1 keyring/24.3.0 rfc3986/2.0.0 colorama/0.4.6 CPython/3.10.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 3f94afc4b4e54a2a19fff345f5dd8b74426054aa6194a0d4e870dc8b5fbbc49f |
|
| MD5 | a560cf2a4e20964b25532391eb48600d |
|
| BLAKE2b-256 | 358e0f7235a05362e11a0da7ed575670353371c96b3526173c054b7378d4496a |
File details
Details for the file timeseriesflattener-1.10.0-py3-none-any.whl.
File metadata
- Download URL: timeseriesflattener-1.10.0-py3-none-any.whl
- Upload date:
- Size: 4.3 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.9.6 readme-renderer/42.0 requests/2.31.0 requests-toolbelt/1.0.0 urllib3/2.1.0 tqdm/4.66.1 importlib-metadata/7.0.1 keyring/24.3.0 rfc3986/2.0.0 colorama/0.4.6 CPython/3.10.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 84f56302f670a2eeb0af25f0841366436fe10a9ab2eff0c460711371aeff625b |
|
| MD5 | 5fd3b29af92b94519ed42b4cb64c9852 |
|
| BLAKE2b-256 | 52fefefd36db6c4a1a4b35028665684fd5213f926441957a99e86a72e209cb28 |







