Small customizable multiprocessing multi-proxy crawler.

Project description






An highly customizable crawler that uses multiprocessing and proxies to download one or more websites following a given filter, search and save functions.
REMEMBER THAT DDOS IS ILLEGAL. DO NOT USE THIS SOFTWARE FOR ILLEGAL PURPOSE.
Installing TinyCrawler
pip install tinycrawlerPreview (Test case)
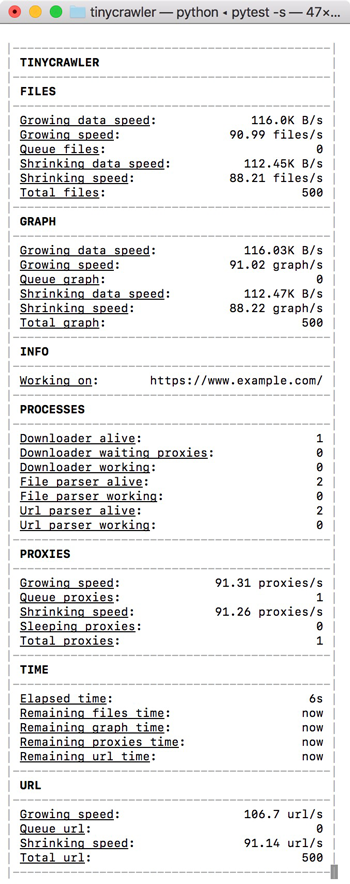
This is the preview of the console when running the test_base.py.
Usage example
from tinycrawler import TinyCrawler
from bs4 import BeautifulSoup
def url_validator(url:str)->bool:
"""Return if page at given url is to be downloaded."""
if "http://www.example.com/my/path" not in url:
return False
return True
def file_parser(response: 'Response', logger: 'Log')->str:
"""Parse downloaded page into document to be saved.
response: 'Response', response object from requests.models.Response
logger: 'Log', a logger to log eventual errors or infos
Return None if the page should not be saved.
"""
soup = BeautifulSoup(response.text, 'lxml')
example = soup.find("div", {"class": "example"})
if example is None:
return None
return example.get_text()
my_crawler = TinyCrawler(
use_cli=True, # True to use the command line interface, False otherwise
directory="my_path_for_website" # Path for where to save website
)
my_crawler.load_proxies("path/to/my/proxies.json")
my_crawler.set_url_validator(url_validator)
my_crawler.set_file_parser(file_parser)
my_crawler.run("http://www.example.com/my/path/index.html")Proxies are expected to be in the following format:
[
{
"ip": "89.236.17.108",
"port": 3128,
"type": [
"https",
"http"
]
},
{
"ip": "128.199.141.151",
"port": 3128,
"type": [
"https",
"http"
]
}
]License
The software is released under the MIT license.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
tinycrawler-1.6.0.tar.gz
(13.9 kB
view hashes)







