A Pytorch implementation of Proximal Policy Optimization for transfomer language models.




Project description

TRL - Transformer Reinforcement Learning
Full stack transformer language models with reinforcement learning.



What is it?

trl is a full stack library where we provide a set of tools to train transformer language models and stable diffusion models with Reinforcement Learning, from the Supervised Fine-tuning step (SFT), Reward Modeling step (RM) to the Proximal Policy Optimization (PPO) step. The library is built on top of the transformers library by 🤗 Hugging Face. Therefore, pre-trained language models can be directly loaded via transformers. At this point most of decoder architectures and encoder-decoder architectures are supported. Refer to the documentation or the examples/ folder for example code snippets and how to run these tools.
Highlights:
SFTTrainer: A light and friendly wrapper aroundtransformersTrainer to easily fine-tune language models or adapters on a custom dataset.RewardTrainer: A light wrapper aroundtransformersTrainer to easily fine-tune language models for human preferences (Reward Modeling).PPOTrainer: A PPO trainer for language models that just needs (query, response, reward) triplets to optimise the language model.AutoModelForCausalLMWithValueHead&AutoModelForSeq2SeqLMWithValueHead: A transformer model with an additional scalar output for each token which can be used as a value function in reinforcement learning.- Examples: Train GPT2 to generate positive movie reviews with a BERT sentiment classifier, full RLHF using adapters only, train GPT-j to be less toxic, Stack-Llama example, etc.
How PPO works
Fine-tuning a language model via PPO consists of roughly three steps:
- Rollout: The language model generates a response or continuation based on query which could be the start of a sentence.
- Evaluation: The query and response are evaluated with a function, model, human feedback or some combination of them. The important thing is that this process should yield a scalar value for each query/response pair.
- Optimization: This is the most complex part. In the optimisation step the query/response pairs are used to calculate the log-probabilities of the tokens in the sequences. This is done with the model that is trained and and a reference model, which is usually the pre-trained model before fine-tuning. The KL-divergence between the two outputs is used as an additional reward signal to make sure the generated responses don't deviate to far from the reference language model. The active language model is then trained with PPO.
This process is illustrated in the sketch below:
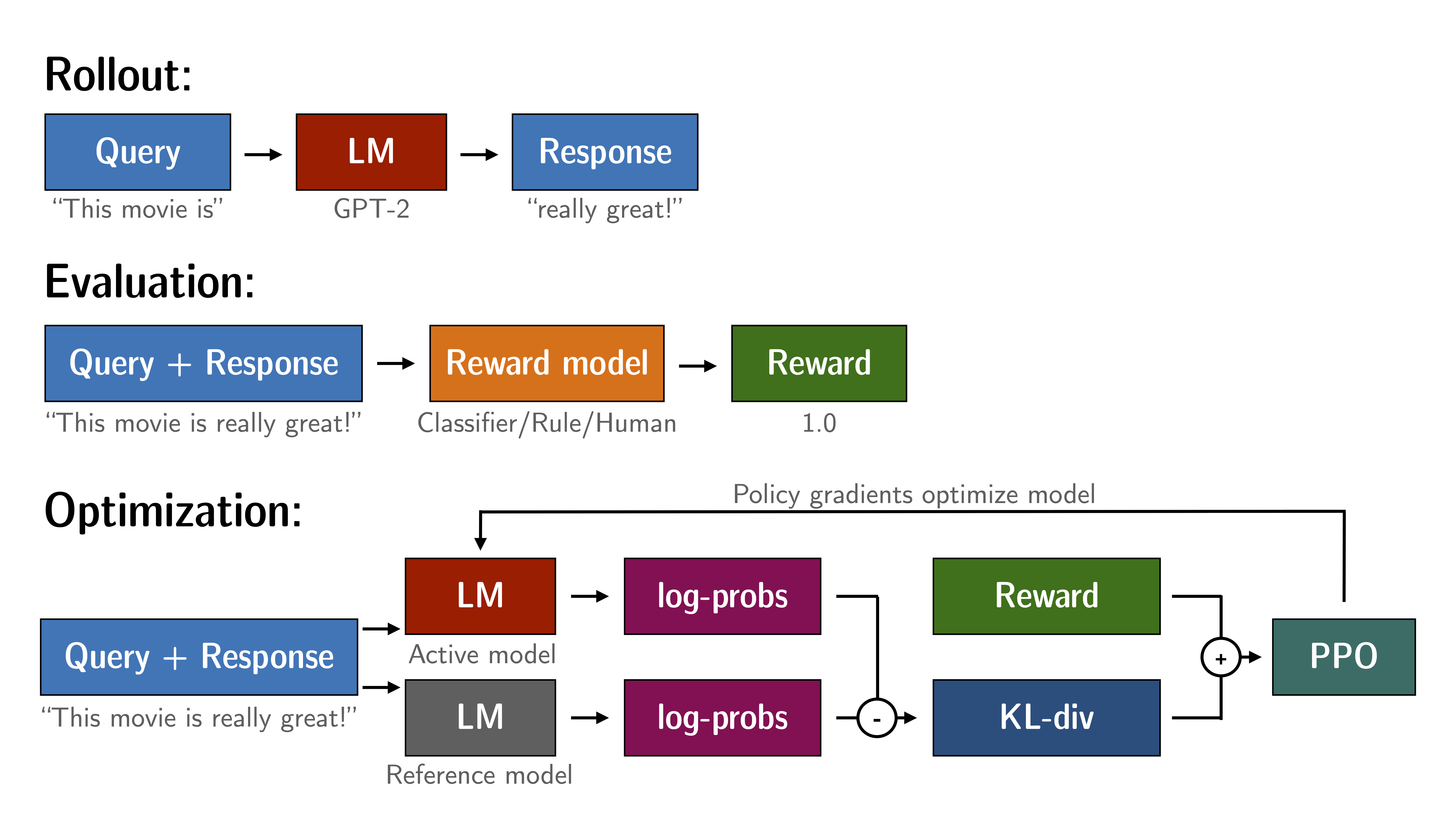
Figure: Sketch of the workflow.
Installation
Python package
Install the library with pip:
pip install trl
From source
If you want to run the examples in the repository a few additional libraries are required. Clone the repository and install it with pip:
git clone https://github.com/huggingface/trl.git
cd trl/
pip install .
If you wish to develop TRL, you should install in editable mode:
pip install -e .
How to use
SFTTrainer
This is a basic example on how to use the SFTTrainer from the library. The SFTTrainer is a light wrapper around the transformers Trainer to easily fine-tune language models or adapters on a custom dataset.
# imports
from datasets import load_dataset
from trl import SFTTrainer
# get dataset
dataset = load_dataset("imdb", split="train")
# get trainer
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
# train
trainer.train()
RewardTrainer
This is a basic example on how to use the RewardTrainer from the library. The RewardTrainer is a wrapper around the transformers Trainer to easily fine-tune reward models or adapters on a custom preference dataset.
# imports
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from trl import RewardTrainer
# load model and dataset - dataset needs to be in a specific format
model = AutoModelForSequenceClassification.from_pretrained("gpt2", num_labels=1)
tokenizer = AutoTokenizer.from_pretrained("gpt2")
...
# load trainer
trainer = RewardTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
)
# train
trainer.train()
PPOTrainer
This is a basic example on how to use the PPOTrainer from the library. Based on a query the language model creates a response which is then evaluated. The evaluation could be a human in the loop or another model's output.
# imports
import torch
from transformers import AutoTokenizer
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_model
from trl.core import respond_to_batch
# get models
model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
model_ref = create_reference_model(model)
tokenizer = AutoTokenizer.from_pretrained('gpt2')
# initialize trainer
ppo_config = PPOConfig(
batch_size=1,
)
# encode a query
query_txt = "This morning I went to the "
query_tensor = tokenizer.encode(query_txt, return_tensors="pt")
# get model response
response_tensor = respond_to_batch(model, query_tensor)
# create a ppo trainer
ppo_trainer = PPOTrainer(ppo_config, model, model_ref, tokenizer)
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0)]
# train model for one step with ppo
train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)
References
Proximal Policy Optimisation
The PPO implementation largely follows the structure introduced in the paper "Fine-Tuning Language Models from Human Preferences" by D. Ziegler et al. [paper, code].
Language models
The language models utilize the transformers library by 🤗 Hugging Face.
Citation
@misc{vonwerra2022trl,
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang},
title = {TRL: Transformer Reinforcement Learning},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/huggingface/trl}}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
File details
Details for the file trl-0.7.2.tar.gz.
File metadata
- Download URL: trl-0.7.2.tar.gz
- Upload date:
- Size: 105.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 93a2a7923e491f725a09d8048b27602b9165b7535d01f580a01ef49c98c5a5d6 |
|
| MD5 | 05dc41fce048eec5f0fc3fd7ca623ea7 |
|
| BLAKE2b-256 | e79be2a52164ce00e9bd00951de02b7685bdde43af8aa29c58e8e4daeb84f8b9 |
File details
Details for the file trl-0.7.2-py3-none-any.whl.
File metadata
- Download URL: trl-0.7.2-py3-none-any.whl
- Upload date:
- Size: 124.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 82887f222ec9b67a55ad6096491ede5a64110b4ee41da19a2e80b4c53bf6564e |
|
| MD5 | 430e9fc58749f227cda18915eb785ae1 |
|
| BLAKE2b-256 | ceb2b0e9c7a15d666aebe83ed72b6a3bec869be88246ddf22d8953f3eee61e22 |







